Ultra Messaging is a software layer, supplied in the form of a dynamic library (shared object), which provides applications with message delivery functionality that adds considerable value to the basic networking services contained in the host operating system. The UMP and UMQ products also include a "Store" daemon that implements Persistence. The UMQ product also includes a "broker" daemon that implements Brokered Queuing.
See UM Glossary for Ultra Messaging terminology, abbreviations, and acronyms.
Ultra Messaging is supported on a variety of platforms. There are three general categories of supported platforms:
- Core platforms: Linux, Windows, Solaris. These are built and shipped every release of UM.
- On-demand Platforms: AIX, HP-UX, Stratus (VOS), HP-NonStop (OSS), OpenVMS. These are only built and shipped by request from users.
- VM and Containers: UM can run in virtualized environments, including containers and VMs. See Virtualized Environments
In addition, Darwin (Mac OS) is supported (on demand) for development and test purposes. We do not support Darwin for production.
- Note
- There are many different distributions of Linux and many different releases of all operating systems. Informatica does not certify UM on specific distributions or versions of operating systems. We do keep our test lab current and test on recent versions of the Core platforms. And we support users on the OS versions that they use in production. But we do not formally certify.
Applications access Ultra Messaging features through the Ultra Messaging Application Programming Interface (API). Ultra Messaging includes the following APIs: the UM C API, the UM Java API, and the UM .NET API. For details on these APIs, see:
These APIs are very similar, and for the most part, this document concentrates on the C API. The translation from C functions to Java or .NET methods should be reasonably straightforward; see Quick Start Guide for sample applications in C, Java, and .NET. See also C Example Source Code, Java Example Source Code, and C# Example Source Code.
The UMQ product also supports the JMS API via the ActiveMQ broker.
The UM product is highly configurable to allow optimization over a wide variety of use cases. See Configuration Introduction for more information.
The three most important design goals of Ultra Messaging are to minimize message latency (the time that a given message spends "in transit"), maximize throughput, and ensure delivery of all messages under a wide variety of operational and failure scenarios. Ultra Messaging achieves these goals by not duplicating services provided by the underlying network whenever possible. Instead of implementing special messaging servers and daemons to receive and re-transmit messages, Ultra Messaging routes messages primarily with the network infrastructure at wire speed. Placing little or nothing in between the sender and receiver is an important and unique design principle of Ultra Messaging.
A UM application can function as a publisher (sometimes call a "source"), or a subscriber (sometimes called a "receiver"). A publishing application sends messages, and a subscribing application receives them. (It is also common for an application to function as both publisher and subscriber; we separate the concepts for organizational purposes.)
License Key <-
Before you can use UM, you must obtain a valid license key. A license key comes in two forms: a file and a string.
A license key file is a normal text file containing 4 lines. For example:
Product=UME,UMQ,LBM,UMDRO Organization=My Company Expiration-Date=never License-Key=xxxx xxxx xxxx xxxx
A license key string is a single line of normal text which combines the above 4 lines, separated by colons. For example:
Product=UME,UMQ,LBM,UMDRO:Organization=My Company:Expiration-Date=never:License-Key=xxxx xxxx xxxx xxxx
The key (file or string) can be supplied to UM in two different ways: XML configuration file and environment.
License Via XML Configuration File <-
If you use XML Configuration Files to configure the UM library, you can specify a license key file using the UM Element "<license>" with format="filename". For example:
<?xml version="1.0" encoding="UTF-8" ?> <um-configuration version="1.0"> <license format="filename">my_um_license.txt</license> ...
Alternatively, you can supply the license information as a string in the XML with format="string":
<?xml version="1.0" encoding="UTF-8" ?>
<um-configuration version="1.0">
<license format="string">
Product=UME,UMQ,LBM,UMDRO:Organization=My Company:Expiration-Date=never:License-Key=xxxx xxxx xxxx xxxx
</license>
...
Note that you cannot supply a license key in Plain Text Configuration Files ("flat" files). See License Via Environment.
License Via Environment <-
You can specify a license key file using the environment variable LBM_LICENSE_FILENAME. For example:
export LBM_LICENSE_FILENAME="my_um_license.txt"
Alternatively, you can supply a license information as a string in the environment variable LBM_LICENSE_INFO. For example:
export LBM_LICENSE_INFO="Product=UME,UMQ,LBM,UMDRO:Organization=My Company:Expiration-Date=never:License-Key=xxxx xxxx xxxx xxxx"
Messaging Paradigms <-
UM supports three basic messaging paradigms (sometimes called Quality Of Service, or QOS):
Sometimes people equate those paradigms with the UM product names "UMS", "UMP", and "UMQ". But this is not accurate. The UMP product supports both streaming and persistence. You can write streaming applications with UMP. The UMQ product supports streaming, persistence, and queuing. You can write streaming or persistent applications with UMQ.
Streaming <-
The UMS, UMP, and UMQ products support "Streaming" as their basic messaging paradigm. With Streaming, messages are sent directly from publisher to subscriber (no broker). A subscriber to a given topic joins the data stream of a publisher of that topic to receive messages. Messages sent during times that the subscriber is not joined are generally not available to the subscriber (live-only), although see Late Join.
Persistence <-
The UMP and UMQ products support Streaming and Persistence messaging paradigms. Persistence, sometimes called "durable" or "guaranteed" messages, saves messages sent by a publisher in non-volatile storage so that subscribers can recover missed messages under a variety of failure scenarios. If multiple subscribers exist for the same topic, each subscriber will get all messages sent by the publisher.
Persistence includes a component known as the persistent Store, which provides stable storage (disk or memory) of message streams.
UM delivers persisted messages from publisher to subscriber with very low latency by using the same technology as Streaming. This offers the functionality of durable subscriptions and confirmed message delivery.
(FYI - you will see references to "UME" in the configuration and APIs for persistence. "UME" is an earlier abbreviation for "UMP".)
For full details on UM Persistence, see the UM Guide for Persistence.
Queuing <-
The UMQ product supports Streaming, Persistence, and Queuing messaging paradigms. Queuing supports "load balancing" whereby published messages can be distributed across a set of subscribers such each message is only handled by one of the subscribers.
UMQ supports both Brokered queuing (where the Queue is a separate component which can store messages independent of the source and receiver), and Ultra Load Balancing (ULB), where the Queue is memory-based and resides in the source.
For full details on UM Queuing, see the UM Guide to Queuing.
Messages <-
The primary function of UM is to transport application messages from a publisher to one or more subscribers. For the purposes of UM, a message is a sequence of bytes, the parsing and interpretation of which is the responsibility of the application.
Since UM does not parse or interpret the messages, UM cannot reformat messages for architectural differences in a heterogeneous environment. For example, UM does not do byte-swapping between big and little endian CPUs.
However, there are some specific exceptions to this rule:
- The Self Describing Messaging feature is a separate library that allows the construction and parsing of structured messages as arbitrary name/value pairs.
- The Pre-Defined Messages feature is another separate library that allows the construction and parsing of structured messages.
- The Message Properties feature allows the setting of structured metadata which is sent along with an application message.
Message Integrity <-
To minimize latency and CPU overhead, UM relies on the Operating System and the Network equipment to ensure the integrity of message data. That is, UM does not add a checksum or digital signature to detect message corruption. Modern network hardware implements very reliable CRCs.
However, we have encountered a case of a microwave-based link that apparently did not use a strong error detection method. This user reported occasional packet corruptions.
We also encountered a situation where an Operating System and a network interface card were configured in an unusual way which led to reproducible undetected packet corruption.
Users who wish to reduce the possibility of message corruption to near-zero will want to implement some sort of message checksum or digital signature outside of UM. (Message Properties could be used to carry the checksum or signature.)
Message Metadata <-
It is sometimes useful for applications to send a message with additional metadata associated with the message. This metadata could be simply added to the message itself, but it is sometimes preferred that the metadata be separated from the message data.
For example, some organizations wrap UM in their own messaging middleware layer that provides a rich set of domain-specific functionality to their applications. This domain-specific functionality allows applications to be written more easily and quickly. However, that layer may need to add its own state-maintenance information which is independent from the application's message data. This middleware data can be supplied either as metadata attached to the message, or as separate non-application messages which are tagged with metadata. (The latter approach is often preferred when application messages must be sent with the minimum possible latency and overhead; adding metadata to a message adds processing overhead, so sending application messages without metadata is the most efficient.)
There are two different UM features that allow adding metadata to messages:
- Message Properties - a general system of typed name/value pairs.
- Application Headers - an older (deprecated) system of attaching small binary values.
Informatica generally recommends the use of Message Properties over Application headers.
Topic Structure and Management <-
UM offers the Publish/Subscribe model for messaging ("Pub/Sub"), whereby one or more receiver programs express interest in a topic ("subscribe"), and one or more source programs send to that topic ("publish"). So, a topic can be thought of as a data stream that can have multiple producers and multiple consumers. One of the functions of the messaging layer is to make sure that all messages sent to a given topic are distributed to all receivers listening to that topic. So another way of thinking of a topic is as a generalized destination identifier - a message is sent "to" a topic, and all subscribers receive it. UM accomplishes this through an automatic process known as topic resolution.
(There is an exception to this Publish/Subscribe model; see Immediate Messaging.)
A topic is just an arbitrary string. For example:
Orders Market/US/DJIA/Sym1
It is not unusual for an application system to have many thousands of topics, perhaps even more than a million, with each one carrying a very specific range of information (e.g. quotes for a single stock symbol).
It is also possible to configure receiving programs to match multiple topics using wildcards. UM uses powerful regular expression pattern matching to allow applications to match topics in a very flexible way. Messages cannot be sent to wildcarded topic names. See UM Wildcard Receivers.
Message Ordering <-
UM normally ensures that received messages are delivered to the application in the same order as they were sent. However, this only applies to a specific topic from a single publisher. UM does not guarantee to retain order across different topics, even if those topics are carried on the same Transport Session. It also does not guarantee order within the same topic across different publishers. For users that need to retain order between different topics from a single publisher, see Spectrum.
Alternatively, it is possible to enforce cross-topic ordering in a very restrictive use case:
- The topics are from a single publisher (context),
- The topics are mapped to the same transport session,
- The Transport Session is configured for TCP (receiver-paced), IPC (receiver-paced), or SMX,
- The subscriber is in the same Topic Resolution Domain (TRD) as the publisher (no DRO in the data path),
- The messages being received are "live" - not being recovered from Late Join, OTR, or Persistence,
- The subscriber is not participating in Queuing,
- The subscriber is not using Hot Failover (HF).
Topic Resolution Overview <-
Topic Resolution ("TR") is a set of protocols and algorithms used internally by Ultra Messaging to establish and maintain shared state. Here are the basic functions of TR:
- Receiver discovery of sources.
- DRO routing information distribution.
- Persistent Store name resolution.
- Fault tolerance.
For more information, see Topic Resolution Description.
Topic Resolution Domain <-
A "Topic Resolution Domain" (TRD) is a set of applications and UM components which share the same Topic Resolution configuration and therefore participate in the TR protocols with each other. The key characteristic of a TRD is that all UM instances communicate directly with each other.
In small deployments of UM, a single TRD is all that is needed.
For larger deployments, especially deployments that are geographically separated with bandwidth-limited WAN links, the deployment is usually divided into multiple TRDs. Each TRD uses a different TR configuration, such that the applications in one TRD don't communicate directly applications in another TRD. The DRO is used to interconnect TRDs and provide connectivity between TRDs.
For more information, see Topic Resolution Description.
Messaging Reliability <-
Users of a messaging system expect every sent message to be successfully received and processed by the appropriately subscribed receivers with the lowest possible latency, 100% of the time. However, this would require perfect networks and computers that can handle unlimited load at infinite speed with complete reliability. Real world networks, computers, and software systems have limitations and are subject to overload and failure, which can lead to message loss.
One job of a messaging system is to detect lost messages and take additional steps to arrange their successful recovery. But again, the limits of hardware and software robustness can make 100% reliability impractical. Part of UM's power is to give the user tools to make intelligent trade-offs between reliability and other important factors, like memory consumption, delivery latencies, hardware redundancies, etc.
Unrecoverable Loss <-
There are two important concepts when talking about loss:
- Simple Loss - usually a case of lost packets due to an overloaded component. UM can be configured in a variety of ways to recover simple loss.
- Unrecoverable Loss - usually a case where a user-configured constraint has been exceeded and the messaging system has to give up trying to recover the lost data.
Simple loss is undesirable, even if the messaging system is able to recover the loss. Any recovery mechanism adds delay to the ultimate delivery of the message, and most uses have limits on the amount of time they are willing to wait for recovery. For example, consider a network hardware outage that takes 10 minutes to repair. A user might have a 5 minutes limit on the age of a message. Thus, the user would like messages sent during the first 5 minutes of the 10-minute outage to simply be declare unrecoverable. Messages sent during the last 5 minutes should be recovered and delivered.
However, when the messaging layer gives up trying to recover messages, it is important for the application software to be informed of this fact. UM delivers unrecoverable loss events to the application followed by subsequent messages successfully received. Applications can use those unrecoverable loss events to take corrective action, like informing the end user, and possibly initiating a re-synchronization operation between distributed components.
Obviously unrecoverable loss is considered a serious event. However, even simple loss should be monitored by users. Daily data rates tend to increase over time. A "clean" network this month might have overload-related simple loss next month, which might progress to unrecoverable loss the month after that.
UM does not deliver specific events to the application when simple loss is detected and successfully recovered. Instead, users have a variety of tools at their disposal to monitor UM transport statistics, which includes counters for simple loss. Applications themselves can use the UM API to "self-monitor" and alert end users when simple loss happens. Or external monitoring applications can be written to receive transport statistics from many applications, and provide a central point where small problems can be detected and dealt with before they become big problems.
See Packet Loss for an extended discussion of packet loss and how UM deals with it.
There are some special cases of unrecoverable loss that deserve additional description:
Head Loss <-
When an application wants to publish messages, it creates one or more UM sources for topics. The design of UM is such that a subscriber discovers the sources of interest and joins them. The process of receivers discovering and joining sources (in UM it is called "Topic Resolution") takes a non-zero amount of time. Since UM is a fully-distributed system with no central master broker, the publisher has no way of knowing when the subscribers have completed the discovery/join process. As a result, it is possible for a publisher to create its sources and send messages, and some of those messages might not reach all of the subscribed receivers.
For many UM-based applications, this is not a problem. Consider a market data distribution system. The market data is a continuous stream of updates with no beginning or end. When a receiver joins, it has no expectation to get the "first" message; it joins at an arbitrary point in the stream and starts getting messages from that point.
But there are other applications where a sender comes up and wants to send a request to a pre-existing receiver. In this case, the sender is very interested in avoiding head loss so that the receiver will get the request.
UM's Persistence feature does a rigorous job of recovering from head loss. UM's Late Join feature is sometimes used by streaming receivers to recover from head loss, although it requires care in the case of a receiver restart since late join can also delivery duplicate messages.
Leading Loss <-
The behavior described in this section does not apply to Persisted data streams where delivery of all messages is important.
For Streaming (non-persisted) data streams, once a receiver successfully joins a source, it should start getting messages. However, there are some circumstances which interfere with the initial message reception.
For example, if a sender is sending a series of very large messages, those messages are fragmented, broken into smaller pieces and sent serially. If a receiver joins the message stream after the first message of a large message has already gone by, the receiver will no longer be able to successfully reassemble that first message. In UM versions prior to 6.12, this led to delivery of one or more Unrecoverable Loss events to the application receiver callback prior to delivery of the first successfully-received message.
Some users attempt to use the Late Join feature to avoid this problem, but the Late Join feature depends on a circular buffer of message fragments. Requesting Late Join may well recover the initial fragment of the message currently under transmission, but it might also recover the final fragments of the message before that. That leads to an unrecoverable loss event for that previous message.
As a final example, suppose that a receiver joins a source during a period of severe overload leading to packet loss. The receiver may not be able to get a full message until the overload condition subsides. This can deliver one or more unrecoverable loss events prior to the first successfully delivered message.
In all of these examples, UM has either gotten no messages or incomplete messages during the startup phase of a new receiver. Starting in UM version 6.12, UM will not deliver unrecoverable loss events to the application in these cases. Once UM is able to successfully deliver its first message to a receiver, UM will enable the delivery of unrecoverable loss events.
This matches what most programmers want to see. They are not interested in messages that came before their first, but they are interested in any gaps that happen after that first message.
Be aware that pre-6.12 versions of UM do deliver leading unrecoverable loss events to the application under some circumstances, leading application developers to implement their own filter for those leading events. Those applications can safely upgrade to 6.12 or beyond; their filter will simply never be executed since UM filters the leading events first.
Finally, remember that it is important for UM-based systems to be monitored for transport statistics, including loss. Since leading unrecoverable loss events are now suppressed (and even pre-6.12 were not reliably delivered in all cases), the transport stats should be used to determine the "health" of the network.
- Note
- Persisted receivers should not suppress leading unrecoverable loss. However, this behavior was mistakenly applied to persisted receivers in UM version 6.12 - 6.16.1 (see bug 11338). Starting in UM version 6.17, the leading loss suppression behavior has been removed from persisted receivers.
Tail Loss <-
Packet loss is a fact of life. Temporary overloads of network hardware can lead to dropped packets. UM receivers are designed to recover those lost packets from the sender, but that recovery takes greater than zero time.
Suppose a application has some messages to send, and then exits. You could have a situation where the last message sent fell victim to a network drop. If the publisher exits immediately, the receivers may not have had enough time to recover the lost packets; may not even have detected the loss.
If the delivery of those tail messages is important, UM's persistence functionality should be used. A sender should delay its exit until the persistence layer informs it that all messages are "stable".
Non-persistent applications can implement an application-level handshake where the receivers tell the senders that they have successfully processed the final message.
Sometimes, delivery of the final message is not of critical importance. In that case, some application developers choose to simply introduce a delay of a second or two after the last message is sent before the sources are deleted. This will give UM a chance to detect and recover any lost messages.
See Preventing NAK Storms with NAK Intervals and Preventing Undetected Unrecoverable Loss for configuration details related to tail loss.
Burst Loss <-
UM's "burst loss" feature is no longer recommended. All known use cases for the burst loss feature are better accomplished through other means. For example, controlling latency after loss should be done using NAK-related and OTR-related configuration options. Informatica recommends disabling the burst loss feature by setting the configuration options delivery_control_maximum_burst_loss (receiver) and delivery_control_maximum_burst_loss (hfx) to 1,000,000,000.
When setting the burst loss options, be sure to include all subscribers, including all instances of UM Stores, DROs, and UMDS servers.
This is especially important for persistent receivers and Stores.
Feature Description
Normally, when the Delivery Controller detects a gap in topic sequence numbers of received message fragments, it waits for a NAK generation interval (defaults to 10 seconds) before declaring the missing message fragments unrecoverably lost. This wait time allows the underlying transport layer to attempt to retrieve the missing message fragments.
The configuration options delivery_control_maximum_burst_loss (receiver) and delivery_control_maximum_burst_loss (hfx) specify a size for a contiguous gap in topic sequence numbers beyond which the gap is defined to be a "burst loss". When this happens, the delivery controller immediately declares the entire gap to be unrecoverably lost and resets its loss-handling structures.
Note that the burst loss feature does not reduce NAKs and retransmissions. If burst loss is invoked, the underlying transport layer will still attempt to recover the lost messages. NAK-based protocols will continue to send NAKs and retransmissions. However, the delivery controller will discard any successfully recovered messages because they were already declared unrecoverable as part of the burst loss event.
For burst loss, a single LBM_MSG_UNRECOVERABLE_LOSS_BURST event is delivered for the entire sequence number gap. Contrast this with simple (not burst) loss events, where a separate LBM_MSG_UNRECOVERABLE_LOSS event will be delivered to the receiver for each lost sequence number.
- Note
- The burst loss control takes priority over all recovery methods. For example, if the subscriber is receiving persistent data and OTR is enabled, a gap longer than delivery_control_maximum_burst_loss will immediately declare the gap as unrecoverable without trying to use OTR to recover.
Finally, be aware that successfully-received but buffered messages can be discarded when a burst loss is detected. For example, let's say that topic sequence number 10 is lost, and number 11 through 30 are successfully received. Datagrams 11 through 30 will be buffered, awaiting datagram 10 being retransmitted. But if the next topic sequence number is 1055, that exceeds the burst loss threshold, which clears the entire order map, discarding messages 11 through 30. The application sees message 9, followed by a burst loss notification, followed by message 1055.
UM Software Stack <-
Here is a simplified diagram of the software stack:
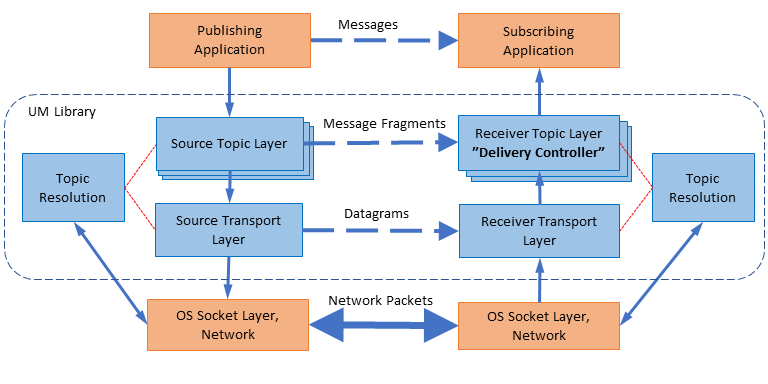
At the bottom is the operating system socket layer, the computer hardware, and the network infrastructure. UM opens normal network sockets using standard operating system APIs. It expects the socket communications to operate properly within the constraints of the operational environment. For example, UM expects sent datagrams to be successfully delivered to their destinations, except when overload conditions exist, in which case packet loss is expected.
The UM library implements a Transport Layer on top of Sockets. The primary responsibility of the Transport Layer is to reliably route datagrams from a publishing instance instance of UM to a receiving instance of UM. If datagram delivery fails, the Transport Layer detects a gap in the data stream and arranges retransmission.
UM implements a Topic Layer on top of its Transport Layer. Publishers usually map multiple topics to a Transport Session, therefore there can be multiple instances of the topic layer on top of a given transport layer instance ("Transport Session"). The Topic layer is responsible for UM fragmentation of messages (splitting large application messages into datagram-sized pieces) and sending them on the proper Transport Session. On the receiving side, the Topic Layer (by default) reassembles fragmented messages, makes sure they are in the right order, and delivers them to the application. Note that the receive-side Topic Layer has a special name: the Delivery Controller.
In addition to those layers is a Topic Resolution module which is responsible for topic discovery and triggering the receive-side joining of Transport Sessions.
Delivery Controller <-
The interaction between the receiver Transport Layer and the Delivery Controller (receive-side Topic Layer) deserves some special explanation.
In UM, publishing applications typically map multiple topic sources to a Transport Session. These topics are multiplexed onto a single Transport Session. A subscribing application will instantiate an independent Delivery Controller for each topic source on the Transport Session that is subscribed. The distribution of datagrams from the Transport Session to the appropriate Delivery Controller instances is a de-multiplexing process.
In most communication stacks, the transport layer is responsible for both reliability and ordering - ensuring that messages are delivered in the same order that they were sent. The UM division of functionality is different. It is the Delivery Controller which re-orders the datagrams into the order originally sent.
The transport layer delivers datagrams to the Delivery Controller in the order that they arrive. If there is datagram loss, the Delivery Controller sees a gap in the series of topic messages. It buffers the post-gap messages in a structure called the Order Map until transport layer arranges retransmission of the lost datagrams and gives them to the Delivery Controller. The Delivery Controller will then deliver to the application the re-transmitted message, followed by the buffered messages in proper order.
To prevent unbounded memory growth during sustained loss, there are two configuration options that control the size and behavior of the Order Map: delivery_control_maximum_total_map_entries (context) and otr_message_caching_threshold (receiver).
This is an important feature because if a datagram is lost and requires retransmission, significant latency is introduced. However, because the Transport Layer delivers datagrams as they arrive, the Delivery Controller is able to deliver messages for topics that are unaffected by the loss. See Example: Loss Recovery for an illustration of this.
This design also enables the UM "Arrival Order Delivery" feature directly to applications (see Ordered Delivery). There are some use cases where a subscribing application does not need to receive every message; it is only important that it get the latest message for a topic with the lowest possible latency. For example, an automated trading application needs the latest quote for a symbol, and doesn't care about older quotes. With Arrival Order delivery, the transport layer will attempt to recover a lost datagram, an unavoidable latency. While waiting for the retransmission, a newer datagram for that topic might be received. Rather than waiting for the retransmitted lost datagram, the Delivery Controller will immediately deliver the newer datagram to the application. Then, when the lost datagram is retransmitted, it will also be delivered to the application. (Note: with arrival order delivery, the Order Map does not need to buffer any messages since all messages are delivered immediately on reception.)
Applications can track when Delivery Controllers are created and deleted using the source_notification_function (receiver) configuration option. This is generally preferable to using Receiver BOS and EOS Events.
UM Threading <-
Ultra Messaging is designed for event-driven, asynchronous, distributed applications. Threads are used to implement the asynchronous behavior, with application callbacks being made from UM threads independently from application threads.
The UM Context Object owns a thread called the "context thread". This thread waits for network activity and handles much of the protocol work for UM. In particular, the context thread is responsible for reading messages from the network socket, preparing them, and delivering them to the application's receiver callback function.
However, the context thread often is not involved in the sending of application messages. An application thread calls the UM send function, and in a typical case, that thread flows through the UM code and makes the socket "send" call. An exception to this is if Implicit Batching is used and a timeout trigger the sending of a partial batch; in this case it is the context thread that sends the message.
The context thread can either be created implicitly when the context is created (Embedded Mode), or the application can choose to create the context thread external to UM and "donate" it to a context (Sequential Mode).
There are some Other Specialized Threads that the context can create, depending on which UM features you use.
Embedded Mode <-
When you create a context (lbm_context_create()) with the UM configuration option operational_mode (context) set to embedded (the default), UM creates an independent thread, called the context thread, which handles timer and socket events, and does protocol-level processing, like retransmission of dropped packets.
Sequential Mode <-
Ultra Messaging typically relies on certain independent threads to perform a variety of its functions. For example, network messages are received by either a context thread or an XSP thread.
By default, UM creates the necessary threads internally using the operating system's thread primitives. However, there are times where an application needs more control. Here are two example use cases:
- The application wants to create the threads so that specific thread attributes can be set as part of creating the threads. For example, CPU affinity, execution priority, even stack size.
- The application wants to serialize all UM operations without the use of any independent threads of execution. In this case, the application may want to have a single thread which executes application code and UM code serially.
These goals can be met using "sequential" mode. With this mode, UM does not create the thread. It becomes the application's responsibility to call the event processing API. For use case 1 above, the application typically creates its own independent thread which simply calls the event processing API in a loop. For use case 2 above, the application calls the event processing API from its main thread.
Context Sequential Mode <-
When you create a context (C API: lbm_context_create()), by default a separate independent thread is created. This is the "context thread".
You enable Sequential mode by setting the configuration option operational_mode (context) to the value "sequential". For example:
context operational_mode sequential
The event processing C API for the context is lbm_context_process_events() or lbm_context_process_events_ex(). Java: LBMContext.processEvents().
- Warning
- If using sequential mode and fd_management_type "wincompport", the thread that creates the context must not exit while the context is active. Furthermore, you gain a small performance improvement if the thread that creates the context is the same thread that calls lbm_context_process_events().
XSP Sequential Mode <-
An XSP is a specialized form of a context. When you create an XSP (C API: lbm_xsp_create()), by default a separate independent thread is created. This is the "XSP thread".
You enable Sequential mode by setting the configuration option operational_mode (xsp) to the value "sequential". For example:
xsp operational_mode sequential
The event processing C API for XSP is lbm_xsp_process_events(). Java: LBMXSP.processEvents().
- Warning
- If using sequential mode and fd_management_type "wincompport", the thread that creates the XSP must not exit while the context is active. Furthermore, you gain a small performance improvement if the thread that creates the context is the same thread that calls lbm_xsp_process_events().
IPC Sequential Mode <-
When a receiver joins an IPC source's transport, by default the context dynamically creates an independent thread to service the IPC shared memory. This is the "IPC thread".
You enable Sequential mode by setting the configuration option transport_lbtipc_receiver_operational_mode (context) to the value "sequential". For example:
context transport_lbtipc_receiver_operational_mode sequential
The event processing C API for IPC is lbm_context_process_lbtipc_messages(). The Java API does not support IPC sequential mode.
Other Specialized Threads <-
In addition to the context thread, there are other UM features which rely on specialized threads:
- The Transport LBT-SMX feature, when used, creates its own specialized receive thread. However, unlike the context thread and the LBT-IPC threads, the creation of the LBT-SMX thread is handled by UM. There is no sequential mode for the LBT-SMX thread.
- The DBL transport acceleration feature, when used, creates its own specialized receive thread. However, unlike the context thread and the LBT-IPC threads, the creation of the DBL thread is handled by UM; there is no sequential mode for the DBL thread.
- The Automatic Monitoring feature, when used, creates an independent context to publish statistics via UM, and a second internal thread for sampling data. The creation of the automatic monitoring threads is handled by UM; there is no sequential mode for the automatic monitoring threads.
- The TCP-based Topic Resolution, when used, creates its own thread to handle communication with the SRSes.
Deleting UM Objects <-
Before you can delete a given UM object, you must first delete all associated objects. For example, before deleting a context, you must delete all sources and receivers associated with that context.
The general order of object deletion is:
-
Cancel UM Timers ("cancel" instead of "delete").
-
Delete any outstanding request objects.
-
Delete sources and receivers, and cancel Registered File Descriptors. ("Receivers" includes wildcard, hf, and hfx receivers.)
-
Delete XSP(s).
-
Delete context(s).
- Delete event queue(s). See "Deleting an Event Queue" for more information.
Some important warnings:
- When deleting a source object, any messages waiting to be sent due to implicit batching or rate limiter might not be sent (if deleting the source also deletes the transport session). Also, any subscribers sending retransmission requests will be ignored.
- For objects that have application callbacks (e.g. receivers), there can be a race condition where the object deletion function returns but an application callback is still executing. See the Callback After Delete.
- In UM's Java and .NET APIs, each object should be explicitly deleted, usually by calling its "close" method. You should not simply release all references to a UM object and expect the garbage collector to do the cleanup.
Callback After Delete <-
For objects with application callbacks, there are circumstances where the delete function successfully returns to the caller while its callback is still executing. This can lead to race conditions and hard-to-diagnose bugs. For example, an application might delete a receiver object and then immediately delete some resources (memory, etc) that the receiver callback uses. But if the receiver callback is executing at the same time that the resources are being deleted, you can get corrupted memory and crashes.
For most object types, this can only happen if the deleted object is associated with an event queue. However, for UM Timers and Registered File Descriptors, you can have callback execution continuing after the cancel returns even if no event queue is used.
One effective technique of avoiding this race condition is called "event sync". An alternative for C programs is to use the C API Extended Delete.
Event Sync <-
The "event sync" technique works with all APIs and object types, with or without an event queue. It is not a separate UM feature; rather it is a technique of using a UM timer to synchronize threads.
The event sync technique consists of deleting one or more objects, and then scheduling a zero-duration timer with a "deletion complete" callback. The timer is associated with the same context as the object(s) being deleted. If the object(s) being deleted are associated with an event queue, the timer should be associated with the same event queue.
Since the timer has a duration of zero, it expires immediately. The UM context thread and/or event queue will finish whatever it is doing and expire the timer. For the non-event queue case, the timer expiration callback is executed immediately by the context. If the timer is associated with an event queue, the dispatch thread will finish whatever it is doing and execute the timer expiration callback. This guarantees that any executing callback for the object being deleted will be completed before the event sync callback is executed.
It is common for a program shutting down to delete hundreds, or even thousands of source and/or receiver objects. It is usually not necessary to perform an event sync for each object. You can delete all of the source and receiver objects and then perform a single event sync to guarantee that all callbacks are done. Then resources used by the callbacks can be safely cleaned up.
See event_sync for C and Java examples.
C API Extended Delete <-
For a C application deleting an object that is associated with an event queue, there is an "extended" delete function which notifies the application via callback when UM guarantees no further callbacks are executing.
The C functions are:
- lbm_context_delete_ex()
- lbm_cancel_timer_ex()
- lbm_cancel_fd_ex()
- lbm_src_delete_ex()
- lbm_rcv_delete_ex()
- lbm_request_delete_ex()
- lbm_wildcard_rcv_delete_ex()
- lbm_hf_rcv_delete_ex()
- lbm_hfx_delete_ex()
- lbm_hfx_rcv_delete_ex()
Note that the "cancel callback" might be invoked synchronously with the call to the ..._ex() function, or it might be invoked asynchronously by the event queue dispatch thread.
Note that the Java and .NET APIs do not have this extended form of object deletion; Informatica recommends using Event Sync.
DRO <-
The Ultra Messaging Dynamic Routing Option (DRO) consists of a daemon named "tnwgd" that bridges disjoint Topic Resolution Domains (TRDs) by effectively forwarding control and user traffic between them. Thus, the DRO facilitates WAN routing where multicast routing capability is absent, possibly due to technical obstacles or enterprise policies.
The DRO transfers multicast and/or unicast topic resolution information, thus ensuring that receivers in disjoint topic resolution domains from the source can receive the topic messages to which they subscribe.
See the Dynamic Routing Guide for more information.
Late Join <-
In many applications, a new receiver may be interested in messages sent before that receiver joins the source's transport session. The Ultra Messaging Late Join feature allows a new receiver to obtain previously-sent messages from a source. Without the Late Join feature, the receiver would only deliver messages sent after the receiver successfully joins the source's transport session. With Late Join, the source locally stores recently sent messages according to its Late Join configuration options, and a new receiver is able to retrieve those messages.
For late join to happen, the source must be configured to offer it, and the receiver must be configured to participate.
Source-side configuration options:
- late_join (source)
- retransmit_retention_age_threshold (source)
- retransmit_retention_size_limit (source)
- retransmit_retention_size_threshold (source)
- request_tcp_interface (context)
Receiver-side configuration options:
- use_late_join (receiver)
- retransmit_request_interval (receiver)
- retransmit_request_message_timeout (receiver)
- retransmit_request_outstanding_maximum (receiver)
- late_join_info_request_interval (receiver)
- late_join_info_request_maximum (receiver)
- retransmit_initial_sequence_number_request (receiver)
- retransmit_message_caching_proximity (receiver)
- response_tcp_interface (context)
- Note
- With Smart Sources, the following configuration options have limited or no support:
- You cannot use Late Join with Queuing functionality (UMQ).
Request/Response <-
Ultra Messaging also offers a Request/Response messaging model. A publisher (the requester) sends a message to a topic. Every receiving application listening to that topic gets a copy of the request. One or more of those receiving applications (responder) can then send one or more responses back to the original requester. Ultra Messaging sends the request message via the normal pub/sub method, whereas Ultra Messaging delivers the response message directly to the requester.
An important aspect of the Ultra Messaging Request/Response model is that it allows the application to keep track of which request corresponds to a given response. Due to the asynchronous nature of Ultra Messaging requests, any number of requests can be outstanding, and as the responses come in, they can be matched to their corresponding requests.
Request/Response can be used in many ways and is often used during the initialization of Ultra Messaging receiver objects. When an application starts a receiver, it can issue a request on the topic the receiver is interested in. Source objects for the topic can respond and begin publishing data. This method prevents the Ultra Messaging source objects from publishing to a topic without subscribers.
Be careful not to be confused with the sending/receiving terminology. Any application can send a request, including one that creates and manages Ultra Messaging receiver objects. And any application can receive and respond to a request, including one that creates and manages Ultra Messaging source objects.
- Note
- You cannot use Request/Response with Queuing functionality.
For more details, see Request/Response Model.
Registered File Descriptors <-
The UM C API running on Unix supports an application creating its own network socket and registering it with the UM context. This allows state changes of the file descriptor (e.g. readable, writable) to be monitored by the UM context. The application provides a callback function that UM invokes when the file descriptor state changes.
This is a rarely-used feature of UM, mostly by market data feed handlers.
Java and .NET sockets are not supported. Windows is also not supported.
To register and cancel an application file descriptor with a context, use:
To register and cancel an application file descriptor with an XSP, use:
- lbm_xsp_register_fd()
- lbm_xsp_cancel_fd() (no "_ex()" form is available)
When canceling a registration, the guidelines for Deleting UM Objects must be followed. Pay special attention to Callback After Delete.
UM Transports <-
A source application uses a UM transport to send messages to a receiver application. An Ultra Messaging transport type is built on top of a standard IP protocol. For example, the UM transport type "LBT-RM" is built on top of the standard UDP protocol using standard multicast addressing. The different Ultra Messaging transport types have different trade-offs in terms of latency, scalability, throughput, bandwidth sharing, and flexibility. The publisher chooses the transport type that is most appropriate for the data being sent, at the topic level. A programmer might choose different transport types for different topics within the same application.
Se Transport Types for the different types of UM transports available.
Transport Sessions <-
An Ultra Messaging publisher can make use of very many topics - possibly over a million. Ultra Messaging maps those topics onto a much smaller number of Transport Sessions. A Transport Session can be thought of as a specific running instance of a transport type, running within a context. A given Transport Session might carry a single topic, or might carry tens of thousands of topics.
A publishing application can either explicitly map each topic source to specific Transport Sessions, or it can make use of an automatic mapping of sources to a default pool of Transport Sessions. If explicitly mapping, the application must configure a new source with identifying information to specify the desired Transport Session. The form of this identifying information depends on the transport type. For example, in the case of the LBT-RM transport type, a Transport Session is identified by a multicast group IP address and a destination port number. Alternatively, if the application does not specify a Transport Session for a new topic source, a Transport Session is implicitly selected from the default pool of Transport Sessions, configured when the context was created. For example, with the LBT-RM transport type, the default pool of implicit Transport Sessions is created with a range of multicast groups, from low to high, and the destination port number. Note that at context creation, the Transport Sessions in the configured default pool are not immediately activated. As topic sources are created and mapped to Transport Sessions, those Transport Sessions are activated.
There are many cases where a transport session is identified using a Source String (minus the bracketed topic index).
- Note
- When two contexts are in use, each context may be used to create a topic source for the same topic name. These sources are considered separate and independent, since they are owned by separate contexts. This is true regardless of whether the contexts are within the same application process or are separate processes. A Transport Session is also owned by a context, and sources are mapped to Transport Sessions within the same context. So, for example, if application process A creates two contexts, ctx1 and ctx2, and creates a source for topic "current_price" in each context, the sources will be mapped to completely independent Transport Sessions. This can even be true if the same Transport Session identification information is supplied to both. For example, if the source for "current_price" is created in ctx1 with LBT-RM on multicast group 224.10.10.10 and destination port 14400, and the source for the same topic is created in ctx2, also on LBT-RM with the same multicast group and destination port, the two Transport Sessions will be separate and independent, although a subscribing application will receive both Transport Sessions on the same network socket.
Subscribing to a Transport Session <-
A receiving application might subscribe to a small subset of the topics that a publisher has mapped to a given Transport Session. In most cases, the subscribing process will receive all messages for all topics on that Transport Session, and the UM library will discard messages for topics not subscribed. This user-space filtering does consume system resources (primarily CPU and bandwidth), and can be minimized by carefully mapping topics onto Transport Sessions according to receiving application interest (having receivers). (Certain transport types allow that filtering to happen in the publishing application; see transport_source_side_filtering_behavior (source).)
When a subscribing application creates its first receiver for a topic, UM will join any and all Transport Sessions that have that topic mapped. The application might then create additional receivers for other topics on that same Transport Session, but UM will not "join" the Transport Session multiple times. It simply sets UM internal state indicating the topic subscriptions. When the publisher sends its next message of any kind on that Transport Session, the subscribing UM will deliver a BOS event (Beginning Of Stream) to all topic receivers mapped to that Transport Session, and will consider the Transport Session to be active. Once active, any subsequent receivers created for topics mapped to that same Transport Session will deliver an immediate BOS to that topic receiver.
If the publisher deletes a topic source, the subscribing application may or may not get an immediate EOS event (End Of Stream), depending on different circumstances. For example, in many cases, the deletion of topic sources by a publisher will not trigger an EOS event until all sources mapped to a Transport Session are deleted. When the last topic is deleted, the Transport Session itself is deleted, and an EOS event might then be delivered to all topic receivers that were mapped to that Transport Session. (The use of resolver_send_final_advertisements (source), TCP-Based Topic Resolution Details, or DROs can change this behavior.) Note that for UDP transports, the deletion of a Transport Session by the publisher is not immediately detected by a subscriber, but rather requires the expiration of an activity timeout.
Be aware that in a deployment that includes the DRO, BOS and EOS may only indicate the link between the receiver and the local DRO portal, not necessarily full end-to-end connectivity. Subscribing application should not use BOS and EOS events as an accurate and timely indication of the creation and deletion of sources by a publisher.
- Note
- Non-multicast Ultra Messaging transport types can use source-side filtering to decrease user-space filtering on the receiving side by doing the filtering on the sending side. However, be aware that system resources consumed on the source side affect all receivers, and that the filtering for multiple receivers must be done serially, whereas letting the receivers do the filtering allows that filtering to be done in parallel, only affecting those receivers that need the filtering.
Transport Session Differences <-
There are a few subtle differences in behavior of transport sessions depending on which transport type is being used.
As sources are created but not explicitly assigned to a specific transport session, UM will assign the source to a transport session in the default pool, in a "round-robin" fashion. But how is the default pool populated with transport sessions?
- Transport LBT-RM - the range of multicast groups from transport_lbtrm_multicast_address_low (context) to transport_lbtrm_multicast_address_high (context) defines the default pool. Note that an LBT-RM transport session is also specified with a destination port, but that port is not specified as a range and is not iterated to create multiple transport sessions.
- Transport LBT-IPC and Transport LBT-SMX - the range of IDs, low to high, defines the default pool. See transport_lbtipc_id_low (context) to transport_lbtipc_id_high (context) for IPC, or transport_lbtsmx_id_low (context) to transport_lbtsmx_id_high (context) for SMX.
- Transport TCP, Transport LBT-RU - both transport types have a range of ports that the default pool is populated from, but the number of transport sessions in the default pool is not simply the port low-to-high difference. Instead, both have a "maximum ports" option that limits the number of transport sessions automatically created. This is because the port low-to-high range is often made large so that multiple application processes can share from it, with each process limited to the maximum ports setting. See transport_tcp_port_low (context) to transport_tcp_port_high (context) and transport_tcp_maximum_ports (context) for TCP, or transport_lbtru_port_low (context) to transport_lbtru_port_high (context) and transport_lbtru_maximum_ports (context) for LBT-RU.
An application can configure a source to a specific transport session, either in the default pool, or outside of it. For example, an application might use transport_lbtrm_multicast_address (source) to assign a source to a multicast group that is outside of the low-to-high range.
The different source transport types differ in how this kind of "outside of the default pool" assignment affects the transport session default pool:
- Transport LBT-RM, Transport LBT-IPC, and Transport LBT-SMX - the explicitly added transport session outside of the configured default pool range does not affect the default pool. For example, assigning a source to a multicast group outside of the low-to-high range does not affect the default pool. Subsequent sources created without a specific multicast group will only be assigned to groups within the low-to-high range. Assigning a source to a transport session that is outside the low-to-high range will prevent other sources from sharing that transport session.
- Transport TCP, Transport LBT-RU - the explicitly added transport session will be added to the default pool. For example, if the low port is 12000 and the high port is 12049 and the maximum ports if 5, the publishing context might assign ports 12000 - 12004 to the default pool. If the publisher then creates a source assigned to port 12020 and another assigned to port 12099, both of those transport sessions will be added to the default pool, making it 7 transport sessions. In particular, creating a source without a specific port assigned will be automatically assigned to one of the default pool transport sessions, and so might be assigned to port 12020 or 12099. Assigning a source to a transport session outside of the low-to-high range does not prevent other sources from sharing the transport session.
See the configuration section for each transport type for specifics on how Transport Sessions are created:
- TCP Transport Session Management
- LBT-RM Transport Session Management
- LBT-RU Transport Session Management
- LBT-IPC Transport Session Management
- LBT-SMX Transport Session Management
With the UMQ product, a ULB source makes use of the same transport types as Streaming, but a Brokered Queuing source must use the broker transport.
Flexible LBT-RU Topic Assignment <-
Starting in UM version 6.17, the user is given more flexibility in assigning topics to LBT-RU transport sessions.
Topics are assigned to RU transport sessions by specifying a source port with transport_lbtru_port (source). For example, in an XML configuration file you might have:
<contexts>
<context>
<sources>
<topic topicname="topic1">
<options type="source">
<option name="transport" default-value="lbtru"/>
<option name="transport_lbtru_port" default-value="12000"/>
</options>
</topic>
<topic topicname="topic2">
<options type="source">
<option name="transport" default-value="lbtru"/>
<option name="transport_lbtru_port" default-value="12000"/>
</options>
</topic>
</sources>
</context>
</contexts>
This tells UM to map topic1 and topic2 to the same transport session, and use the port 12000 for that session.
This causes a problem if two applications want to publish to the same topic are run on the same host. If they both use the same configuration, they will both try to open port, and the second one will fail.
Starting with UM version 6.17, the user can specify transport_lbtru_allow_ephemeral (source). For example:
<contexts>
<context>
<sources>
<topic topicname="topic1">
<options type="source">
<option name="transport" default-value="lbtru"/>
<option name="transport_lbtru_port" default-value="12000"/>
<option name="transport_lbtru_allow_ephemeral" default-value="1"/>
</options>
</topic>
<topic topicname="topic2">
<options type="source">
<option name="transport" default-value="lbtru"/>
<option name="transport_lbtru_port" default-value="12000"/>
<option name="transport_lbtru_allow_ephemeral" default-value="1"/>
</options>
</topic>
</sources>
</context>
</contexts>
This allows the second instance to attempt to bind to port 12000, and upon failing will instead allocate an ephemeral port.
Note that the port number specified for transport_lbtru_port is still used for topic grouping. In the above example, both topic1 and topic2 will be mapped to the same ephemeral port.
Transport Pacing <-
Pacing refers to the controlling of when messages can be sent. Source Pacing is when the publisher of messages controls when messages are sent, and Receiver Pacing is when the subscribers can essentially push back on the publisher if the publisher is sending faster than the subscribers can consume messages.
Source Pacing <-
In its simplest case, source pacing means that the publishing application controls when to send messages by having messages to send. For example, market data distribution system sends messages when the exchanges it is monitoring sends updates. The subscribers must be able to accept those messages at the rates that the exchanges send them.
A slow subscriber will fall behind and can lose data if buffers overflow. There is no way for a slow subscriber to "push back" on a fast publisher.
Some of Ultra Messaging's transport types have features that allow the publisher to establish upper limits on the outgoing message data. For example, LBT-RM has the transport_lbtrm_data_rate_limit (context) configuration option. If the application attempts to send too many messages in too short a time, the send function can block for a short time, or return an error indicating that it attempted to exceed the configured rate limit. This is still called source pacing because the rate limit is optional and is under the control of the publisher.
The source-paced transports are:
- Transport TCP (can be configured for source or receiver pacing)
- Transport LBT-RU (source pacing only)
- Transport LBT-RM (source pacing only)
- Transport LBT-IPC (can be configured for source or receiver pacing)
Receiver Pacing <-
In a receiver-paced transport, a publisher still attempts to send when it has messages to send, but the send function can block or return an error if the publisher is sending faster than the slowest subscribed receiver can consume. There is a configurable amount of buffering that can be used to allow the publisher to exceed the consumption rate for short periods of time, but when those buffers fill, the sender will be prevented from sending until the buffers have enough room.
The receiver-paced transports are:
- Transport TCP (can be configured for source or receiver pacing)
- Transport LBT-IPC (can be configured for source or receiver pacing)
- Transport LBT-SMX (receiver-pacing only)
However, it is generally inadvisable to rely on receiver pacing to ensure reliable system operation. Subscribers should be designed and provisioned to support the maximum possible incoming data rates. The reasons for this recommendation are described below.
Receiver Queuing <-
This use case is not related to the Queuing paradigm. It is referring to the use of a software queue between the context thread which receives the UM message and the application thread which processes the message.
A receiver-paced transport does not necessarily mean that a slow application will push back on a fast publisher. Suppose that the actual message reception action by UM's context thread is fast, and the received messages are placed in an unbounded memory queue. Then, one or more application threads take messages from the queue to process them. If those application threads don't process messages quickly enough, instead of pushing back on the publisher, the message queue will grow.
For example, the UM Event Queue Object is an unbounded memory-based queue. You could use Transport TCP configured for receiver pacing, but if the subscriber uses an event queue for message delivery, then a slow consumer will not slow down the publisher. Instead the subscriber's event queue will grow without bound, eventually leading to an out-of-memory condition.
Pacing and DRO <-
Transport pacing refers to the connection within a a Topic Resolution Domain (TRD) from source to receiver. If multiple TRDs are connected with a DRO, there can be multiple hops between the originating publisher and the final subscriber, with the DROs providing proxy sources and receivers to pass messages across the hops. The pacing of a particular transport session only applies to the link between the source (or proxy source) and the receiver (or proxy receiver) of a particular hop.
This means that UM does not support end-to-end transport pacing.
For example, if a DRO joins two TRDs, both of which use receiver-paced TCP for transport, a slow receiver might push back on the DRO's proxy source, leading to queuing in the DRO. Since the DRO uses bounded queues, the DRO's queue will fill, leading to dropped messages.
Pacing and Queuing <-
Brokered Queuing is receiver paced between the source and the broker. For ULB queuing, the transport pacing is determined by the chosen transport type.
There is also a form of end-to-end application receiver-pacing with queuing. For both brokered ULB, the size of queue is configurable. As receivers consume messages, they are removed from the queue. If the queue fills due to the source exceeding the consumption rate of the receiver, the next send call will either block or return a "WOULDBLOCK" error until sufficient room opens up in the queue. Note that lifetimes can be configured for messages (to prevent unbounded blocking) and the application can be notified if a message exceeds its lifetime.
See UM Guide to Queuing for more information.
Pacing and Persistence <-
With Persistence, the pacing is layered:
-
At the transport level, pacing is determined by the chosen transport type.
-
At the persistence level, Transport Pacing provides receiver pacing between the source and the Store. This helps to ensure that a publisher sending on a source-paced transport like LBT-RM will not overwhelm the Store.
-
By default, the end-to-end pacing is source-paced. Which is to say that if a subscribed receiver cannot keep up with the publish rate, eventually the receiver can experience unrecoverable loss, although this normally will only happen if the receiver falls further behind than the total size of the Store's repository.
- Alternatively, the end-to-end pacing can be switched to receiver-paced. This is done using RPP: Receiver-Paced Persistence. Note that if a subscribed receiver crashes, it can lead to unbounded blockage of the publisher until the subscriber is successfully restarted.
Suspended Receiver Problem <-
This is a problem that one of our users encountered. Their system used receiver-paced TCP because they wanted the publishing speed to be limited to the rate that the slowest receiver could consume. This was fine until one day the publisher appeared to stop working.
With some help from Support, the problem was trace to a receiver at a particular IP address that was joined to the transport but apparently was not reading any data. It took some time to find the receiver by its IP address, and what they found was a Windows machine with a dialog box telling the user that the process had generated an exception and did the user want abort the process or enter the debugger.
When Windows does this, it suspends the process waiting for user input. In that suspended state, the kernel maintains the network connections, but the process is not able to read any data. So the socket buffers filled up and the publisher's send call blocked.
Event Delivery <-
There are many different events that UM may want to deliver to the application. Many events carry data with them (e.g. received messages); some do not (e.g. end-of-stream events). Some examples of UM events:
- Received message. UM delivers messages on subscribed topics to the receiver.
- Receiver loss. UM can inform the application when a data gap is detected on a subscribed topic that could not be recovered through the normal retransmission mechanism.
- End of Stream. UM can inform a receiving application when a data stream (Transport Session) has terminated.
- Connect and Disconnect events. Source-side events delivered to a publisher when receivers connect to and disconnect from the source's transport session.
- A timer expiring. Applications can schedule timers to expire in a desired number of milliseconds (although the OS may not deliver them with millisecond precision).
- An application-managed file descriptor event. The application can register its own file descriptors with UM to be monitored for state changes (readable, writable, error, etc.).
- New source notification. UM can inform the application when sources are discovered by Topic Resolution.
UM delivers events to the application via callbacks. The application explicitly gives UM a pointer to one of its functions to be the handler for a particular event, and UM calls that function to deliver the event, passing it the parameters that the application requires to process the event. In particular, the last parameter of each callback type is a client data pointer (clientdp). This pointer can be used at the application's discretion for any purpose. It's value is specified by the application when the callback function is identified to UM (typically when UM objects are created), and that same value is passed back to the application when the callback function is called.
There are two methods that UM can use to call the application callbacks: through context thread callback, or event queue dispatch.
In the context thread callback method (sometimes called direct callback), the UM context thread calls the application function directly. This offers the lowest latency, but imposes significant restrictions on the application function. See Event Queue Object.
The event queue dispatch of application callback introduces a dynamic buffer into which the UM context thread writes events. The application then uses a thread of its own to dispatch the buffered events. Thus, the application callback functions are called from the application thread, not directly from the context thread.
With event queue dispatching, the use of the application thread to make the callback allows the application function to make full, unrestricted use of the UM API. It also allows parallel execution of UM processing and application processing, which can significantly improve throughput on multi-processor hardware. The dynamic buffering provides resilience between the rate of event generation and the rate of event consumption (e.g. message arrival rate v.s. message processing rate).
In addition, an UM event queue allows the application to be warned when the queue exceeds a threshold of event count or event latency. This allows the application to take corrective action if it is running too slow, such as throwing away all events older than a threshold, or all events that are below a given priority.
Note that while most UM events can be delivered via event queue, there are some that cannot (e.g. resolver_source_notification_function (context)).
Receiver BOS and EOS Events <-
There are two receive-side events that some applications use but which are not recommended for most use cases:
- LBM_MSG_BOS - Beginning of (transport) Session.
- LBM_MSG_EOS - End of (transport) Session.
The BOS and EOS events are delivered to receivers on a topic basis, but were originally designed to represent the joining and exiting of the underlying Transport Session.
Note that the BOS and EOS receive-side events are very similar to the Source Connect and Disconnect Events.
The BOS event means slightly different things for different transport types. The basic principal is that a UM receiver won't deliver BOS until it has seen some kind of activity on the transport after joining it. For example, a session message for Transport LBT-RM. Or perhaps a TSNI on any of the transport types. Or even an actual user message. Any of these will trigger BOS. But if the newly-joined transport session is completely silent, then BOS is delayed until first activity is detected. Under some configurations, that delay is unbounded.
EOS is also triggered by different things for different transport types. For example, for the TCP transport, a disconnect will trigger EOS for any receivers that were subscribed to topics carried on that transport session. For LBT-RM, an activity timeout can trigger EOS.
However, in recent versions of UM, the meaning of EOS has become more complicated, and no longer necessarily indicates that the transport session has ended. There are circumstances in many versions of UM where a publisher of a source that is in a remote TRD can delete that source, and the receiver will receive a timely EOS, even though the transport session that carried the source stays in effect and joined by the receiver. Starting with UM version 6.10, the configuration option resolver_send_final_advertisements (source) can be used to trigger EOS on receivers in the same TRD, even if the transport session remains joined. Starting with UM version 6.12, TCP-based Topic Resolution will have the same effect. In in a mixed-version UM environment including DROs, it can be difficult to predict when an EOS will be generated for a deleted source.
Be aware that BOS does not necessarily indicate end-to-end connectivity between sources and receivers. In a DRO network, where the source is in a different Topic Resolution Domain (TRD) from the receiver, BOS only indicates the establishment of the transport session between the DRO's proxy source and the receiver.
Also, BOS and EOS do not necessarily come in balanced pairs. For example, if a BOS is delivered to a receiver, and then the subscriber application deletes the receiver object, UM does not deliver an EOS to the receiver callback. Also, it is possible to get an EOS event without first getting a BOS. Let's say that a receiver attempts to join an LBT-RM transport session for a source that was just deleted. BOS will not be delivered because there will be no communication of a user or control message. However, after LBT-RM times out the transport session, it will deliver EOS.
Finally, in some versions of UM, EOS represents the end of the entire transport session, so you can have situations where a publisher deletes a source, but the receiver for that topic does not get an EOS for an unbounded period of time. Let's say that the publisher maps sources for topics X, Y, and Z to the same transport session. Let's further say that a subscriber has a receiver for topic Y. It will join the transport session, get a BOS for receiver Y, and will receive messages that the publisher sends to Y. Now let's say that the publisher deletes the source for topic Y, but keeps the sources for topics X and Z. The subscriber may not be informed of the deletion of the source for Y, and can remain subscribed to the transport session. It won't be until the publisher deletes sources X and Z that it will delete the underlying transport session, which can then deliver EOS to the subscriber. However, if using TCP-based Topic Resolution, this same scenario can produce an EOS event on the receiver immediately.
For these reasons and others, Informatica does not recommend using the BOS and EOS events to indicate "connectedness" between a source and a receiver. Instead, Informatica recommends logging the events in your application log file. If something goes wrong, these messages can assist in diagnosing the problem.
For programmers who are tempted to use BOS and EOS events, Informatica recommends instead using the source_notification_function (receiver) configuration option. This provides receiving applications a callbacks when a Delivery Controller is created and deleted, and is usually what the programmer really wants.
Source Connect and Disconnect Events <-
There are two source-side events that some applications use but which are not recommended for most use cases:
- LBM_SRC_EVENT_CONNECT - Beginning of (transport) Session to receiver.
- LBM_SRC_EVENT_DISCONNECT - End of (transport) Session to receiver.
The Connect and Disconnect events are delivered to source on a topic basis, but actually represent the joining and exiting of the underlying Transport Session to a specific receiver.
- Note
- The Connect and Disconnect events are not available for Transport LBT-RM or Transport LBT-SMX sources.
Note that the Connect and Disconnect source-side events are very similar to the Receiver BOS and EOS Events. However, while BOS and especially EOS have deviated from their pure "transport session" roots, Connect and Disconnect are still purely implemented with respect to the underlying transport session.
Be aware that Connect does not necessarily indicate end-to-end connectivity between sources and receivers. In a DRO network, where the source is in a different Topic Resolution Domain (TRD) from the receiver, Connect only indicates the establishment of the transport session between the DRO's proxy receiver and the source. For example, if a source in TRD1 is sending messages to two receivers in TRD2 via a DRO, the source will only receive a single Connect event when the first of the two receivers subscribe. Note also that the IP and port indicated in the Connect event will be for the DRO portal on TRD1.
Also, since Disconnect represents the end of the entire transport session, you can have situations where a subscriber deletes a receiver, but the source for that topic does not get a Disconnect for an unbounded period of time. Let's say that the publisher maps sources for topics X, Y, and Z to the same transport session. Let's further say that a subscriber has a receiver for topic Y and Z. It will join the transport session, and the source will get Connect events for all three topics, X, Y, and Z. Now let's say that the subscriber deletes the receiver for topic Y, but keeps the receiver for topic Z. The source will not be informed of the deletion of the receiver for Y, since the transport session continues to be maintained. It won't be until the subscriber deletes both receivers, Y and Z, that it will delete the underlying transport session, which can then deliver Disconnect to the source.
For these reasons and others, Informatica does not recommend using the Connect and Disconnect events to indicate "connectedness". Instead, Informatica recommends logging the events in your application log file. If something goes wrong, these messages can assist in diagnosing the problem.
Source Wakeup Event <-
The source event LBM_SRC_EVENT_WAKEUP is delivered to the application when a non-blocking "send" function is called but returns the LBM_EWOULDBLOCK error. When that happens, the message was not sent due to a flow controlling condition. When that flow controlling condition is cleared, UM delivers the wakeup to the source event callback, informing the application that it can resume sending.
The flow controlling conditions are:
- The source uses the TCP (normal), IPC (receiver_paced), or SMX protocol, and one or more receivers are not reading fast enough. When both the receiver's and sender's buffers are full, a non-blocking "send" will return LBM_EWOULDBLOCK. When the slow receiver(s) read more data, the flow control condition is cleared and the wakeup source event is delivered.
- The source uses a UDP-based protocol and the data rate limit is exceeded (see transport_lbtrm_data_rate_limit (context) or transport_lbtru_data_rate_limit (context)). A non-blocking "send" will return LBM_EWOULDBLOCK. When the rate interval expires and the rate limiter adds bandwidth, the flow control condition is cleared and the wakeup source event is delivered.
- The source uses persistence and exceeds a flight size limit (see ume_flight_size (source) and ume_flight_size_bytes (source)). A non-blocking "send" will return LBM_EWOULDBLOCK. When the Store sends stability ACKs to the source and the in-flight message data drops below the limit, the flow control condition is cleared and the wakeup source event is delivered.
In all cases, the wakeup event is delivered by the UM context thread.
However, note that typically a separate thread (created by the application) is calling the non-blocking "send" function. There can be cases where the call to "send" detects the flow control condition, but before it can return LBM_EWOULDBLOCK, the context thread clears the condition and delivers the LBM_SRC_EVENT_WAKEUP event via the the application's source callback. From the application's point of view, this represents the notification of UM's internal state transitions is reversed, with the wakeup appearing to happen before the LBM_EWOULDBLOCK. This potential reversal of event notification is a natural consequence of the design of UM and is not considered a bug. The application must be carefully coded to take this race condition into account.
For example, here's a modified excerpt from the Example lbmsrc.c program (see similar code in Java and .NET):
The wakeup event indicates that a blocked source is no longer blocked. This example uses a global variable to track the blocked state of the source, so the wakeup event clears it.
Here is the application sending code:
The important part of this code is that the global "blocked" flag is set before* the call to lbm_src_send(). If you try to set it after the send function returns, the wakeup event might execute before your sending thread can set it. This will leave "blocked" set even though the wakeup event has already been delivered.
Note that there should be a separate "blocked" variable for each source object the application creates. This flag would typically be placed in a "clientd" structure instead of being a process-global variable.
- Warning
- The above example code is NOT safe for multiple application threads sending to the same source object.
Source Flight Notification Event <-
The source event LBM_SRC_EVENT_FLIGHT_SIZE_NOTIFICATION can be delivered to the application when a source is configured for persistence and has set its ume_flight_size_behavior (source) to "notify".
As the application sends messages, the flight size increases, and as the Store delivers message stability ACKs, the flight size decreases. As the application sends messages increasing the flight size, if it crosses a flight size limit, the internal flight size state for that source becomes "over" and the LBM_SRC_EVENT_FLIGHT_SIZE_NOTIFICATION event is delivered with state LBM_SRC_EVENT_FLIGHT_SIZE_NOTIFICATION_STATE_OVER.
Subsequently, as Store stability acknowledgements are delivered to the source decreasing the flight size, if it goes below the flight size limits, the internal flight size state for that source becomes "under" and the LBM_SRC_EVENT_FLIGHT_SIZE_NOTIFICATION event is delivered with state LBM_SRC_EVENT_FLIGHT_SIZE_NOTIFICATION_STATE_UNDER.
However, these two events are delivered by separate threads. The "OVER" notification is delivered by the application thread calling the "send" function, and the "UNDER" notification is delivered by the UM context receiving the Store's stability ACK. There can be cases where the application will process the two events concurrently, or even in the reverse order that the internal state changed. For example, the actual order of state transitions might be "UNDER", "OVER", "UNDER", but the application will process the events as "UNDER", "UNDER", "OVER". This potential reversal of event notification is a natural consequence of the design of UM and is not considered a bug. The application must be carefully coded to take this race condition into account.
Here is some example code to demonstrate a possible use pattern:
This example uses two global state variables to indicate when the two notification events have been delivered.
Here's some code that checks to see if flight size is "over" and wait for it to be "under" before sending:
This code works because the "over" event is delivered synchronously with the lbm_src_send() function. If lbm_src_send() exceeds the flight size, UM guarantees that the "over" event will be delivered before the send function returns. This guarantee enables the code to handle the "under" event being delivered before the "over" event.
Note that there should be a separate "over_delivered" and "under_delivered" variables for each source object the application creates. These flags would typically be placed in a "clientd" structure instead of being process-global variables.
Also note that unlike the "wakeup" event (described above), getting an "over" event does not prevent the "send" function from successfully sending the message. The point of setting ume_flight_size_behavior (source) to "notify" is to allow the publisher to continue sending in spite of exceeding flight size. But note that doing this can prevent UM from guaranteeing delivery of messages.
- Warning
- The above example code is NOT safe for multiple application threads sending to the same source object.
Rate Controls <-
For UDP-based communications (LBT-RU, LBT-RM, and Topic Resolution), UM network stability is ensured through the use of rate controls. Without rate controls, sources can send UDP data so fast that the network can be flooded. Using rate controls, the source's bandwidth usage is limited. If the source attempts to exceed its bandwidth allocation, it is slowed down.
Setting the rate controls properly requires some planning; see Topics in High Performance Messaging, Group Rate Control for details.
Ultra Messaging's rate limiter algorithms are based on dividing time into intervals (configurable), and only allowing a certain number of bits of data to be sent during each interval. That number is divided by the number of intervals per second. For example, a limit of 1,000,000 bps and an interval of 100 ms results in the limiter allowing 100,000 bits to be sent during each interval. Dividing by 8 to get bytes gives 12,500 bytes per interval.
Data are not sent over a network as individual bytes, but rather are grouped into datagrams. Since it is not possible to send only part of a datagram, the rate limiter algorithm needs to decide what to do if an outgoing datagram would exceed the number of bits allowed during the current time interval. The data transport rate limiter algorithm, for LBT-RM and LBT-RU, differs from the Topic Resolution rate limiter algorithm.
Transport Rate Control <-
With data transport, if an application sends a message and the outgoing datagram would exceed the number of bits allowed during the current time interval, that datagram is queued and the transport type is put into a "blocked" state in the current context. Note that success is returned to the application, even though the datagram has not yet been transmitted.
However, any subsequent sends within the same time interval will not queue, but instead will either block (for blocking sends), or return the error LBM_EWOULDBLOCK (for non-blocking sends). When the time interval expires, the context thread will refresh the number of allowable bits, send the queued datagram, and unblock the transport type.
Note that for very small settings of transport rate limit, the end-of-interval refresh of allowable bits may still not be enough to send a queued full datagram. In that case, the datagram will remain on the queue for additional intervals to pass, until enough bits have accumulated to send the queued datagram. However, it would be very unusual for a transport rate limit to be set that small.
Transport Rate Control Configuration
Configuration parameters of interest are:
- transport_lbtrm_rate_interval (context)
- transport_lbtrm_data_rate_limit (context)
- transport_lbtrm_retransmit_rate_limit (context)
- transport_lbtru_rate_interval (context)
- transport_lbtru_data_rate_limit (context)
- transport_lbtru_retransmit_rate_limit (context)
LBM_EWOULDBLOCK
When non-blocking sends are done (LBM_SRC_NONBLOCK), the send can fail with an error number of LBM_EWOULDBLOCK. This means you have exceeded the rate limit and must wait before sending the message.
Most applications don't need to handle this because they use blocking sends. Instead of returning a failure when the rate limit is exceeded, the send function sleeps until the transport becomes unblocked again, at which point the UM context thread wakes up the sleeping send call. However, there are times that blocking behavior is not permitted. For example, if the application is running as a UM Context thread callback (timer, receiver event, source event, etc), then only non-blocking sends are allowed.
To assist the application in retrying the message send, the UM context thread will deliver the LBM_SRC_EVENT_WAKEUP source event to the application. (This only happens if a non-blocking send was tried and failed with LBM_EWOULDBLOCK.) The application can use that event to re-try sending the message.
Alternatively, exceeding the rate limit can be avoided by increasing the configured rate limit and/or rate interval. This can reduce latency, but also increases the risk of packet loss.
The rate limit controls how many bits can be transmitted during a given second of time. The rate interval controls the "shape" of the transmissions over the second of time.
Adjusting the Rate Interval
A long rate interval will allow intense bursts of traffic to be sent, which can overload switch port queues or NIC ring buffers, leading to packet loss. A short rate interval will reduce the intensity of the bursts, spreading the burst over a longer time, but does so by introducing short delays in the transmissions, which increases message latency.
The LBT-RM default rate interval of 10 milliseconds was chosen to be reasonably "safe" in terms of avoiding loss, at the expense of possible transmission delays. Latency-sensitive applications may require a larger value, but increases the risk of switch or NIC loss.
There is no analytical way of choosing an optimal value for the rate interval. Latency-sensitive users should test different values with intense bursts to find the largest value which avoids packet loss.
Topic Resolution Rate Control <-
With UDP-based Topic Resolution ("TR"), the algorithm acts differently. It is designed to allow at least one datagram per time interval, and is allowed to exceed the rate limit by at most one topic's worth. Thus, the TR rate limiter value should only be considered a "reasonably accurate" approximation.
This approximation can seem very inaccurate at very small rate limits. As an extreme example, suppose that a user configures the sustaining advertisement rate limiter to 1 bit per second. Since the TR rate limiter allows at least one Advertisement (TIR) to be sent per interval, and a TIR of a 240-character topic creates a datagram about 400 bytes long (exact size depends on user options), ten of those per second is 32,000 bits, which is over 3 million percent of the desired rate. This sounds extreme, but understand that this works out to only 10 packets per second, a trivial load for modern networks. In practice, the minimum effective rate limit works out to be one datagram per interval.
For details of Topic Resolution, see Topic Resolution Description.
Operational Statistics <-
UM maintains a variety of transport-level statistics which gives a real-time snapshot of UM's internal handling. For example, it gives counts for transport messages transferred, bytes transferred, retransmissions requested, unrecoverable loss, etc.
The UM monitoring API provides framework to allow the convenient gathering and transmission of UM statistics to a central monitoring point. See Monitoring for more information.
Immediate Messaging <-
UM has an alternate form of messaging that deviates from the normal publish/subscribe paradigm. An "immediate message" can be sent and received without the need for topic resolution. Note that immediate messaging is less efficient than normal source-based messaging and will not provide the same low latency and high throughput.
There are two forms of immediate messaging:
- Unicast Immediate Messaging (UIM) - TCP-based point-to-point.
- Multicast Immediate Messaging (MIM) - flooding-based multicast; use rarely.