Transport TCP <-
The TCP UM transport uses normal TCP connections to send messages from sources to receivers. This is the default transport when it's not explicitly set.
TCP is a good choice when:
- Flow control is desired. For example, when one or more receivers cannot keep up, you wish to slow down the source. But see TCP Flow Control Restrictions.
- Equal bandwidth sharing with other TCP traffic is desired. The source will slow down when general network traffic becomes heavy.
- There are few receivers listening to each topic. Multiple receivers for a topic requires multiple transmissions of each message, which places a scaling burden on the source machine and the network.
- The application is not sensitive to latency. Use of TCP as a messaging transport can result in unbounded latency.
- The messages must pass through a restrictive firewall which does not pass multicast traffic.
Some users choose TCP to avoid unrecoverable loss. However, be aware that network failures can result in TCP disconnects, which can lead to missed messages. Also, if the DRO is being used, messages can be dropped due to full queues in an overloaded DRO, leading to unrecoverable loss.
LBT-TCP's Transport Pacing can be either source-paced or receiver-paced. See transport_tcp_multiple_receiver_behavior (source).
UM's TCP transport includes a Session ID. A UM source using the TCP transport generates a unique, 32-bit non-zero random Session ID for each TCP transport (IP:port) it uses. The source also includes the Session ID in its Topic Resolution advertisement (TIR). When a receiver resolves its topic and discovers the transport information, the receiver also obtains the transport's Session ID. The receiver sends a message to the source to confirm the Session ID.
The TCP Session ID enables multiple receivers for a topic to connect to a source across a DRO. In the event of a DRO failure, UM establishes new topic routes which can cause cached Topic Resolution and transport information to be outdated. Receivers use this cached information to find sources. Session IDs add a unique identifier to the cached transport information. If a receiver tries to connect to a source with outdated transport information, the source recognizes an incorrect Session ID and disconnects the receiver. The receiver can then attempt to reconnect with different cached transport information.
- Note
- To maintain interoperability between version pre-6.0 receivers and version 6.0 and beyond TCP sources, you can turn off TCP Session IDs with the UM configuration option, transport_tcp_use_session_id (source).
TCP Flow Control Restrictions <-
The TCP transport protocol can provide a limited form of flow control. If a publisher is sending messages faster than a subscriber can process them, the publisher's "send" call will "block" to force the sender to slow down to the receiver's rate. (Alternatively, a non-blocking send will return -1 with the error code LBM_EWOULDBLOCK.)
However, be aware that there are restrictions on this use case.
- DRO - The DRO does not support end-to-end flow control. If a DRO is between a source and a slow receiver, the DRO will drop messages, resulting in unrecoverable loss in the receiver.
- Event Queue - If the receiver uses an event queue, a slow receiver can result in unbounded memory growth in the subscriber, rather than slowing down the publisher.
- transport_tcp_multiple_receiver_behavior (source) - if set to "source_paced", the source will drop messages intended for a slow receiver when the socket buffers fill, resulting in unrecoverable loss in the receiver.
If end-to-end application-level flow control is needed, users should implement their own handshakes.
Transport LBT-RU <-
The LBT-RU UM transport adds reliable delivery to unicast UDP to send messages from sources to receivers. This provides greater flexibility in the control of latency. For example, the application can further limit latency by allowing the use of arrival order delivery. See the Knowledge Base article, FAQ: How do arrival-order delivery and in-order delivery affect latency?. Also, LBT-RU is less sensitive to overall network load; it uses source rate controls to limit its maximum send rate.
LBT-RU's Transport Pacing is source-paced.
Since it is based on unicast addressing, LBT-RU can pass through most firewalls. However, it has the same scaling issues as TCP when multiple receivers are present for each topic.
UM's LBT-RU transport includes a Session ID. A UM source using the LBT-RU transport generates a unique, 32-bit non-zero random Session ID for each transport it uses. The source also includes the Session ID in its Topic Resolution advertisement (TIR). When a receiver resolves its topic and discovers the transport information, the receiver also obtains the transport's Session ID.
The LBT-RU Session ID enables multiple receivers for a topic to connect to a source across a DRO. In the event of a DRO failure, UM establishes new topic routes which can cause cached Topic Resolution and transport information to be outdated. Receivers use this cached information to find sources. Session IDs add a unique identifier to the cached transport information. If a receiver tries to connect to a source with outdated transport information, the transport drops the received data and times out. The receiver can then attempt to reconnect with different cached transport information.
- Note
- To maintain interoperability between version pre-3.3 receivers and version 3.3 and beyond LBT-RU sources, you can turn off LBT-RU Session IDs with the UM configuration option, transport_lbtru_use_session_id (source).
- LBT-RU can benefit from hardware acceleration. See Transport Acceleration Options for more information.
Transport LBT-RM <-
The LBT-RM transport adds reliable multicast to UDP to send messages. This provides the maximum flexibility in the control of latency. In addition, LBT-RM can scale effectively to large numbers of receivers per topic using network hardware to duplicate messages only when necessary at wire speed. One limitation is that multicast is often blocked by firewalls.
LBT-RM's Transport Pacing is source-paced.
LBT-RM is a UDP-based, reliable multicast protocol designed with the use of UM and its target applications specifically in mind.
UM's LBT-RM transport includes a Session ID. A UM source using the LBT-RM transport generates a unique, 32-bit non-zero random Session ID for each transport it uses. The source also includes the Session ID in its Topic Resolution advertisement (TIR). When a receiver resolves its topic and discovers the transport information, the receiver also obtains the transport's Session ID.
- Note
- LBT-RM can benefit from hardware acceleration. See Transport Acceleration Options for more information.
NAK Suppression <-
Some reliable multicast protocols are susceptible to "NAK storms" in which a subscriber experiences loss due to overload, and the publisher sends those retransmissions, which makes the subscriber's overload more severe, resulting in an even greater loss rate, which triggers an even greater NAK rate, which triggers an even greater retransmission rate, and so on. This self-reinforcing feedback loop can cause healthy, non-overloaded subscribers to become so overwhelmed with retransmissions that they also experience loss and send NAKs, making the storm worse. Some users of other protocols have experienced NAK storms so severe that their entire network "melts down" and becomes unresponsive.
The Ultra Messaging LBT-RM protocol was designed specifically to prevent this kind of run-away feedback loop using a set of algorithms collectively known as "NAK Suppression". These algorithms are designed to repair occasional loss reasonably quickly, while preventing a crybaby receiver from degrading the overall system.
Note that although UM's Transport LBT-RU does not use Multicast, there are still dangers associated with crybaby receivers. LBT-RU implements most of the same NAK suppression algorithms.
Here are the major elements of UM's NAK suppression algorithms:
-
When a receiver detects datagram loss (missing sequence number), it chooses a random amount of time to back off before sending a NAK (see transport_lbtrm_nak_initial_backoff_interval (receiver)). If the receiver subsequently receives the missing datagram(s) before the timer expires, it cancels the timer and sends no NAK.
This reduces the load in the case of common loss patterns across multiple receivers. Whichever receiver chooses the smallest amount of time sends the NAK, and the retransmission prevents (suppresses) NAKs from the other receivers.
-
The source has a configurable limit on the rate of retransmissions allowed; see transport_lbtrm_retransmit_rate_limit (context). When that rate is reached, the source rejects NAKs for the remainder of the rate limit interval and instead sends NCFs in response to the NAKs. (NCFs suppress receivers from sending NAKs for specific sequence numbers for configurable periods of time.)
- The source has a configurable interval during which it will only send one retransmission for a given sequence number; see transport_lbtrm_ignore_interval (source). If a source receives multiple NAKs for the same sequence number within that interval, only the first will trigger a retransmission. Subsequent NAKs within the ignore interval are rejected, triggering one or more NCFs.
Note that LBT-RM's NCF algorithm was improved in UM version 6.10. Prior to 6.10, the source responds to every rejected NAK with an NCF (if the reason for the rejection is temporary). In UM 6.10 and beyond, only the first rejected NAK within an ignore interval triggers an NCF. Any subsequent NAKs in the same ignore interval are silently discarded. This reduces the NCF rate in a wide variety of loss conditions, which reduces the stress on healthy receivers.
- Warning
- We have seen customers choose configuration values which reduce the protective characteristics of LBT-RM. For example, setting the retransmission rate too high, or the NAK backoff intervals too low. Doing so can reduce loss-induced latency, but can also risk disruptive NAK/retransmission storms which can stress otherwise healthy receivers. Users should request review of their configurations from Informatica's Ultra Messaging support organization.
Comparing LBT-RM and PGM <-
The LBT-RM protocol is very similar to PGM, but with changes to aid low latency messaging applications.
- Topic Mapping - Several topics may map onto the same LBT-RM session. Thus a multiplexing mechanism to LBT-RM is used to distinguish topic level concerns from LBT-RM session level concerns (such as retransmissions, etc.). Each message to a topic is given a sequence number in addition to the sequence number used at the LBT-RM session level for packet retransmission.
- Negative Acknowledgments (NAKs) - LBT-RM uses NAKs as PGM does. NAKs are unicast to the sender. For simplicity, LBT-RM uses a similar NAK state management approach as PGM specifies.
- Time Bounded Recovery - LBT-RM allows receivers to specify a maximum time to wait for a lost piece of data to be retransmitted. This allows a recovery time bound to be placed on data that has a definite lifetime of usefulness. If this time limit is exceeded and no retransmission has been seen, then the piece of data is marked as an unrecoverable loss and the application is informed. The data stream may continue and the unrecoverable loss will be ordered as a discrete event in the data stream just as a normal piece of data.
- Flexible Delivery Ordering - LBT-RM receivers have the option to have the data for an individual topic delivered "in order" or "arrival order". Messages delivered "in order" will arrive in sequence number order to the application. Thus loss may delay messages from being delivered until the loss is recovered or unrecoverable loss is determined. With "arrival-order" delivery, messages will arrive at the application as they are received by the LBT-RM session. Duplicates are ignored and lost messages will have the same recovery methods applied, but the ordering may not be preserved. Delivery order is a topic level concern. Thus loss of messages in one topic will not interfere or delay delivery of messages in another topic.
- Session State Advertisements - In PGM, SPM packets are used to advertise session state and to perform PGM router assist in the routers. For LBT-RM, these advertisements are only used when data are not flowing. Once data stops on a session, advertisements are sent with an exponential back-off (to a configurable maximum interval) so that the bandwidth taken up by the session is minimal.
- Sender Rate Control - LBT-RM can control a sender's rate of injection of data into the network by use of a rate limiter. This rate is configurable and will back pressure the sender, not allowing the application to exceed the rate limit it has specified. In addition, LBT-RM senders have control over the rate of retransmissions separately from new data. This allows the publisher to guarantee a minimum transmission rate even in the face of massive loss at some or all receivers.
- Low Latency Retransmissions - LBT-RM senders do not mandate the use of NCF packets as PGM does. Because low latency retransmissions is such an important feature, LBT-RM senders by default send retransmissions immediately upon receiving a NAK. After sending a retransmission, the sender ignores additional NAKs for the same data and does not repeatedly send NCFs. The oldest data being requested in NAKs has priority over newer data so that if retransmissions are rate controlled, then LBT-RM sends the most important retransmissions as fast as possible.
Transport LBT-IPC <-
The LBT-IPC transport is an Interprocess Communication (IPC) UM transport that allows sources to publish topic messages to a shared memory area managed as a static ring buffer from which receivers can read topic messages. Message exchange takes place at memory access speed which can greatly improve throughput when sources and receivers can reside on the same host.
LBT-IPC's Transport Pacing can be either source-paced or receiver-paced. See transport_lbtipc_behavior (source).
The LBT-IPC transport uses a "lock free" design that eliminates calls to the Operating System and allows receivers quicker access to messages. An internal validation method enacted by receivers while reading messages from the Shared Memory Area ensures message data integrity. The validation method compares IPC header information at different times to ensure consistent, and therefore, valid message data. Sources can send individual messages or a batch of messages, each of which possesses an IPC header.
Note that while the use of Transport Services Provider (XSP) for network-based transports does not conflict with LBT-IPC, it does not apply to LBT-IPC. IPC data flows cannot be assigned to XSP threads.
Sources and LBT-IPC <-
When you create a source with lbm_src_create() and you've set the transport option to IPC, UM creates a shared memory area object. UM assigns one of the transport IDs to this area specified with the UM context configuration options, transport_lbtipc_id_high (context) and transport_lbtipc_id_low (context). You can also specify a shared memory location outside of this range with a source configuration option, transport_lbtipc_id (source), to prioritize certain topics, if needed.
UM names the shared memory area object according to the format, LBTIPC_x_d where x is the hexadecimal Session ID and d is the decimal Transport ID. Example names are LBTIPC_42792ac_20000 or LBTIPC_66e7c8f6_20001. Receivers access a shared memory area with this object name to receive (read) topic messages.
See Transport LBT-IPC Operation Options for configuration information.
Sending over LBT-IPC
To send on a topic (write to the shared memory area) the source writes to the Shared Memory Area starting at the Oldest Message Start position. It then increments each receiver's Signal Lock if the receiver has not set this to zero.
Receivers and LBT-IPC <-
Receivers operate identically to receivers for all other UM transports. A receiver can actually receive topic messages from a source sending on its topic over TCP, LBT-RU or LBT-RM and from a second source sending on LBT-IPC with out any special configuration. The receiver learns what it needs to join the LBT-IPC session through the topic advertisement.
The configuration option transport_lbtipc_receiver_thread_behavior (context) controls the IPC receiving thread behavior when there are no messages available. The default behavior, 'pend', has the receiving thread pend on a semaphore for a new message. When the source adds a message, it posts to each pending receiver's semaphore to wake the receiving thread up. Alternatively, busy_wait can be used to prevent the receiving thread going to sleep. In this case, the source does not need to post to the receiver's semaphore. It simply adds the message to shared memory, which the looping receiving thread detects with the lowest possible latency.
Although 'busy_wait' has the lowest latency, it has the drawback of consuming 100% of a CPU core during periods of idleness. This limits the number of IPC data flows that can be used on a given machine to the number of available cores. (If more busy looping receivers are deployed than there are cores, then receivers can suffer 10 millisecond time sharing quantum latencies.)
For application that cannot afford 'busy_wait', there is another configuration option, transport_lbtipc_pend_behavior_linger_loop_count (context), which allows a middle ground between 'pend' and 'busy_wait'. The receiver is still be configured as 'pend', but instead of going to sleep on the semaphore immediately upon emptying the shared memory, it busy waits for the configured number of times. If a new message arrives, it processes the message immediately without a sleep/wakeup. This can be very useful during bursts of high incoming message rates to reduce latency. By making the loop count large enough to cover the incoming message interval during a burst, only the first message of the burst will incur the wakeup latency.
Topic Resolution and LBT-IPC
Topic resolution operates identically with LBT-IPC as other UM transports albeit with a new advertisement type, LBMIPC. Advertisements for LBT-IPC contain the Transport ID, Session ID and Host ID. Receivers obtain LBT-IPC advertisements in the normal manner (resolver cache, advertisements received on the multicast resolver address:port and responses to queries.) Advertisements for topics from LBT-IPC sources can reach receivers on different machines if they use the same topic resolution configuration, however, those receivers silently ignore those advertisements since they cannot join the IPC transport. See Sending to Both Local and Remote Receivers.
Receiver Pacing
Although receiver pacing is a source behavior option, some different things must happen on the receiving side to ensure that a source does not reclaim (overwrite) a message until all receivers have read it. When you use the default transport_lbtipc_behavior (source) (source-paced), each receiver's Oldest Message Start position in the Shared Memory Area is private to each receiver. The source writes to the Shared Memory Area independently of receivers' reading. For receiver-pacing, however, all receivers share their Oldest Message Start position with the source. The source will not reclaim a message until all receivers have successfully read that message.
Receiver Monitoring
To ensure that a source does not wait on a receiver that is not running, the source monitors a receiver via the Monitor Shared Lock allocated to each receiving context. (This lock is in addition to the semaphore already allocated for signaling new data.) A new receiver takes and holds the Monitor Shared Lock and releases the resource when it dies. If the source is able to obtain the resource, it knows the receiver has died. The source then clears the receiver's In Use flag in it's Receiver Pool Connection.
Similarities with Other UM Transports <-
Although no actual network transport occurs, IPC functions in much the same way as if you send packets across the network as with other UM transports.
- If you use a range of LBT-IPC transport IDs, UM assigns multiple topics sent by multiple sources to all the Transport Sessions in a round robin manner just like other UM transports.
- Transport sessions assume the configuration option values of the first source assigned to the Transport Session.
- Sources are subject to message batching.
Differences from Other UM Transports <-
- Unlike LBT-RM which uses a transmission window to specify a buffer size to retain messages in case they must be retransmitted, LBT-IPC uses the transmission window option to establish the size of the shared memory.
- LBT-IPC does not retransmit messages. Since LBT-IPC transport is essentially a memory write/read operation, messages should not be be lost in transit. However, if the shared memory area fills up, new messages overwrite old messages and the loss is absolute. No retransmission of old messages that have been overwritten occurs. (Note: while transport-level retransmission is not available, IPC is compatible with the Off-Transport Recovery (OTR) feature, which allows for persistent message recovery from the Store, or streaming message recovery from the Source's Late Join buffer.)
- Receivers also do not send NAKs when using LBT-IPC.
- LBT-IPC does not support ordered_delivery (receiver) options. However, if you set ordered_delivery (receiver) 1 or -1, LBT-IPC reassembles any large messages.
- LBT-IPC does not support Rate Limiting.
- LBT-IPC creates a separate receiver thread in the receiving context.
Sending to Both Local and Remote Receivers <-
A source application that wants to support both local and remote receivers should create two UM Contexts with different topic resolution configurations, one for IPC sends and one for sends to remote receivers. Separate contexts allows you to use the same topic for both IPC and network sources. If you simply created two source objects (one IPC, one say LBT-RM) in the same UM Context, you would have to use separate topics and suffer possible higher latency because the sending thread would be blocked for the duration of two send calls.
A UM source will never automatically use IPC when the receivers are local and a network transport for remote receivers because the discovery of a remote receiver would hurt the performance of local receivers. An application that wants transparent switching can implement it in a simple wrapper.
LBT-IPC Configuration Example <-
The following diagram illustrates how sources and receivers interact with the shared memory area used in the LBT-IPC transport:
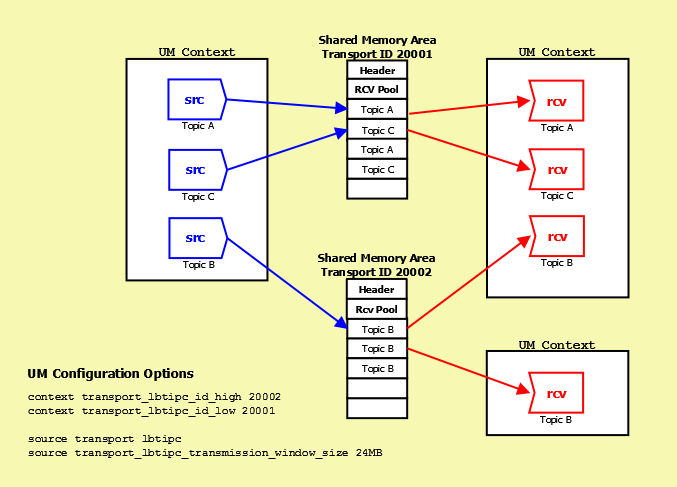
In the diagram above, 3 sources send (write) to two Shared Memory Areas while four receivers in two different contexts receive (read) from the areas. The assignment of sources to Shared Memory Areas demonstrate UM's round robin method. UM assigns the source sending on Topic A to Transport 20001, the source sending on Topic B to Transport 20002 and the source sending on Topic C back to the top of the transport ID range, 20001.
The diagram also shows the UM configuration options that set up this scenario:
- The options transport_lbtipc_id_high (context) and transport_lbtipc_id_low (context) establish the range of Transport IDs between 20001 and 20002.
- The option transport (source) is used to set the source's transport to LBT-IPC.
- The option transport_lbtipc_transmission_window_size (source) sets the size of each Shared Memory Area to 24 MB.
Required privileges <-
LBT-IPC requires no special operating system authorities, except on Microsoft Windows Vista and Microsoft Windows Server 2008, which require Administrator privileges. In addition, on Microsoft Windows XP, applications must be started by the same user, however, the user is not required to have administrator privileges. In order for applications to communicate with a service, the service must use a user account that has Administrator privileges.
Host Resource Usage and Limits <-
LBT-IPC contexts and sources consume host resources as follows:
- Per Source - 1 shared memory area, 1 shared lock (semaphore on Linux, mutex on Microsoft Windows)
- Per Receiving Context - 2 shared locks (semaphores on Linux, one event and one mutex on Microsoft Windows)
Across most operating system platforms, these resources have the following limits.
- 4096 shared memory areas, though some platforms use different limits
- 32,000 shared semaphores (128 shared semaphore sets * 250 semaphores per set)
Consult your operating system documentation for specific limits per type of resource. Resources may be displayed and reclaimed using the LBT-IPC Resource Manager. See also the KB article Managing LBT-IPC Host Resources.
LBT-IPC Resource Manager <-
Deleting an IPC source or deleting an IPC receiver reclaims the shared memory area and locks allocated by the IPC source or receiver. However, if a less than graceful exit from a process occurs, global resources remain allocated but unused. To address this possibility, the LBT-IPC Resource Manager maintains a resource allocation database with a record for each global resource (memory or semaphore) allocated or freed. You can use the LBT-IPC Resource Manager to discover and reclaim resources. See the three example outputs below.
Displaying Resources
$> lbtipc_resource_manager Displaying Resources (to reclaim you must type '-reclaim' exactly) --Memory Resources-- Memory resource: Process ID: 24441 SessionID: ab569cec XportID: 20001 --Semaphore Resources-- Semaphore key: 0x68871d75 Semaphore resource Index 0: reserved Semaphore resource: Process ID: 24441 Sem Index: 1 Semaphore resource: Process ID: 24436 Sem Index: 2
Reclaiming Unused Resources
$> lbtipc_resource_manager -reclaim Reclaiming Resources Process 24441 not found: reclaiming Memory resource (SessionID: ab569cec XPortID: 20001) Process 24441 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 1 Process 24436 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 2
Transport LBT-SMX <-
The LBT-SMX (shared memory acceleration) transport is an Interprocess Communication (IPC) transport you can use for the lowest latency message Streaming.
LBT-RU's Transport Pacing is receiver-paced. If you need source pacing, see Transport LBT-IPC.
Like LBT-IPC, sources can publish topic messages to a shared memory area from which receivers can read topic messages. LBT-SMX is slightly faster than Transport LBT-IPC. However, SMX imposes more limitations than LBT-IPC; see Differences Between LBT-SMX and Other UM Transports.
To achieve the minimum possible latency and jitter, the receive side uses busy waiting exclusively. This means that while waiting for a message, the receiving context has a thread running at 100% CPU utilization. To avoid latency jitter, Informatica strongly recommends pinning the thread to a single core to prevent the operating system from migrating the thread across cores.
Although busy waiting has the lowest latency, it has the drawback of consuming 100% of a CPU core, even during periods of no messages. This limits the number of SMX data flows that can be used on a given machine to the number of available cores. If this is not practical for your use case, Informatica recommends the use of Transport LBT-IPC.
There are two forms of API calls available with LBT-SMX:
- General APIs - the same APIs used with other transports, such as sending messages with lbm_src_send().
- SMX-specific APIs - APIs that further reduce overhead and latency but require a somewhat different code design, such as sending messages with lbm_src_buff_acquire() and lbm_src_buffs_complete().
Note that the SMX-specific APIs are not thread safe, and require that the calling application guarantee serialization of calls on a given Transport Sessions.
LBT-SMX operates on the following Ultra Messaging platforms:
- 64-bit SunOS (X86 only)
- 64-bit Linux
- 64-bit Windows
The "latency ping/pong" example programs demonstrate how to use the SMX-specific API.
For C: Example lbmlatping.c and Example lbmlatpong.c.
For Java: Example lbmlatping.java and Example lbmlatpong.java.
For .NET: Example lbmlatping.cs and Example lbmlatpong.cs.
Many other example applications can use the LBT-SMX transport by setting the transport (source) configuration option to "LBT-SMX":
source transport LBT-SMX
However, you cannot use LBT-SMX with example applications for features not supported by LBT-SMX, such as Example lbmreq.c, Example lbmresp.c, Example lbmrcvq.c, or Example lbmwrcvq.c.
The LBT-SMX configuration options are similar to the LBT-IPC transport options. See Transport LBT-SMX Operation Options for more information.
You can use Automatic Monitoring, UM API retrieve/reset calls, and LBMMON APIs to access LBT-SMX source and receiver transport statistics. To increase performance, the LBT-SMX transport does not collect statistics by default. Set the UM configuration option transport_lbtsmx_message_statistics_enabled (context) to 1 to enable the collection of transport statistics.
The next few sections provide an in-depth understanding of how SMX works, using the C API as the model. Java and .NET programmers are encouraged to read these sections for the understanding of SMX. There are also sections specific to Java and .NET near the end to provide API details.
Sources and LBT-SMX <-
When you create a source with lbm_src_create() and you've set the transport (source) option to "LBT-SMX", UM creates a shared memory area object. UM assigns one of the transport IDs to this area from a range of transport IDs specified with the UM context configuration options transport_lbtsmx_id_high (context) and transport_lbtsmx_id_low (context). You can also specify a shared memory location inside or outside of this range with the option transport_lbtsmx_id (source) to group certain topics in the same shared memory area, if needed. See Transport LBT-SMX Operation Options for configuration details.
UM names the shared memory area object according to the format, LBTSMX_x_d where x is the hexadecimal Session ID and d is the decimal Transport ID. Example names are LBTSMX_42792ac_20000 or LBTSMX_66e7c8f6_20001. Receivers access a shared memory area with this object name to receive (read) topic messages.
- Note
- For every context created by your application, UM creates an additional shared memory area for control information. The name for these control information memory areas ends with the suffix, _0, which is the Transport ID.
Here are the SMX-specific in C:
- lbm_src_buff_acquire() - obtains a pointer into the source's shared buffer for a new message of the specified length.
- lbm_src_buffs_complete() - informs UM that one or more acquired messages are complete and ready to be delivered to receivers.
- lbm_src_buffs_complete_and_acquire() - a convenience function that is the same as calling lbm_src_buff_acquire() followed immediately by lbm_src_buffs_complete().
- lbm_src_buffs_cancel() - cancels all message buffers acquired but not yet completed.
The SMX-specific APIs fail with an appropriate error message if a sending application uses them for a source configured to use a transport other than LBT-SMX.
- Note
- The SMX-specific APIs are not thread safe at the source object or LBT-SMX Transport Session levels for performance reasons. Applications that use the SMX-specific APIs for either the same source or a group of sources that map to the same LBT-SMX Transport Session must serialize the calls either directly in the application or through their own mutex.
Sending with SMX-specific APIs <-
Sending with SMX-specific APIs is a two-step process.
-
The publisher first calls lbm_src_buff_acquire(), which returns a pointer into which the publisher writes the message data.
The pointer points directly into the shared memory area. UM guarantees that the shared memory area has at least the value specified with the len parameter of contiguous bytes available for writing when lbm_src_buff_acquire() returns. Note that the acquire function has the potential of blocking (spinning), if the shared memory area is full of messages that are unread by at least one subscribed receiver. If your application set the LBM_SRC_NONBLOCK flag with lbm_src_buff_acquire(), UM immediately returns an LBM_EWOULDBLOCK error condition if the function detects the blocking condition.
Because LBT-SMX does not support fragmentation, your application must limit message lengths to a maximum equal to the value of the source's configured transport_lbtsmx_datagram_max_size (source) option minus 16 bytes for headers. In a system deployment that includes the DRO, this value should be the same as the Datagram Max Sizes of other transport types. See Protocol Conversion.
After the user acquires the pointer into shared memory and writes the message data, the application may call lbm_src_buff_acquire() repeatedly to send a batch of messages to the shared memory area. If your application writes multiple messages in this manner, sufficient space must exist in the shared memory area. lbm_src_buff_acquire() returns an error if the available shared memory space is less than the size of the next message.
-
The publisher calls one of the two following APIs.
- lbm_src_buffs_complete(), which publishes the message or messages to all listening receivers.
- lbm_src_buffs_complete_and_acquire(), which publishes the message or messages to all listening receivers and acquires a new pointer.
Sending over LBT-SMX with General APIs <-
LBT-SMX supports the general send API functions, like lbm_src_send(). These API calls are fully thread-safe. The LBT-SMX feature restrictions still apply (see Differences Between LBT-SMX and Other UM Transports). The lbm_src_send_ex_info_t argument to the lbm_src_send_ex() and lbm_src_sendv_ex() APIs must be NULL when using an LBT-SMX source, because LBT-SMX does not support any of the features that the lbm_src_send_ex_info_t parameter can enable.
Since LBT-SMX does not support an implicit batcher or corresponding implicit batch timer, UM flushes all messages for all sends on LBT-SMX transports done with general APIs, which is similar to setting the LBM_MSG_FLUSH flag. LBT-SMX also supports the lbm_src_flush() API call, which behaves like a thread-safe version of lbm_src_buffs_complete().
- Warning
- Users should not use both the SMX-specific APIs and the general API calls in the same application. Users should choose one or the other type of API for consistency and to avoid thread safety problems.
The lbm_src_topic_alloc() API call generates log warnings if the given attributes specify an LBT-SMX transport and enable any of the features that LBT-SMX does not support. The lbm_src_topic_alloc() returns 0 (success), but UM does not enable the unsupported features indicated in the log warnings. Other API functions that operate on lbm_src_t objects, such as lbm_src_create(), lbm_src_delete(), or lbm_src_topic_dump(), operate with LBT-SMX sources normally.
Because LBT-SMX does not support fragmentation, your application must limit message lengths to a maximum equal to the value of the source's configured transport_lbtsmx_datagram_max_size (source) option minus 16 bytes for headers. Any send API calls with a length parameter greater than this configured value fail. In a system deployment that includes the DRO, this value should be the same as the Datagram Max Sizes of other transport types. See Protocol Conversion.
Receivers and LBT-SMX <-
LBT-SMX receivers can be coded the same as receivers on other UM transports. The msg->data pointer of a delivered lbm_msg_t object points directly into the shared memory area. However, Java and .NET receivers can benefit from some alternate coding techniques. See Java Coding for LBT-SMX and .NET Coding for LBT-SMX.
The lbm_msg_retain() API function operates differently for LBT-SMX. lbm_msg_retain() creates a full copy of the message in order to access the data outside the receiver callback.
- Attention
- You application should not pass the msg->data pointer to other threads or outside the receiver callback until your application has called lbm_msg_retain() on the message.
- Warning
- Any API calls documented as not safe to call from a context thread callback are also not safe to call from an LBT-SMX receiver thread.
Topic Resolution and LBT-SMX
Topic resolution operates identically with LBT-SMX as other UM transports albeit with the advertisement type, LBMSMX. Advertisements for LBT-SMX contain the Transport ID, Session ID, and Host ID. Receivers get LBT-SMX advertisements in the normal manner, either from the resolver cache, advertisements received on the multicast resolver address:port, or responses to queries.
Similarities Between LBT-SMX and Other UM Transports <-
Although no actual network transport occurs, SMX functions in much the same way as if you send packets across the network as with other UM transports.
- If you use a range of LBT-SMX transport IDs, UM assigns multiple topics sent by multiple sources to all the Transport Sessions in a round robin manner just like other UM transports.
- Transport sessions assume the configuration option values of the first source assigned to the Transport Session.
- Source applications and receiver applications based on any of the three available APIs can interoperate with each other. For example, sources created by a C publisher can send to receivers created by a Java receiving application.
Differences Between LBT-SMX and Other UM Transports <-
- Unlike LBT-RM which uses a transmission window to specify a buffer size to retain messages for retransmission, LBT-SMX uses the transmission window option to establish the size of the shared memory. LBT-SMX uses transmission window sizes that are powers of 2. You can set transport_lbtsmx_transmission_window_size (source) to any value, but UM rounds the option value up to the nearest power of 2.
- The largest transmission window size for Java applications is 1 GB.
- The largest possible message size for Java applications is 1 GB.
- LBT-SMX does not retransmit messages. Since LBT-SMX transport only supports receiver pacing, messages are never lost in transit.
- Receivers do not send NAKs when using LBT-SMX.
LBT-SMX is not compatible with the following UM features:
- Arrival Order, Fragments Not Reassembled (ordered_delivery 0).
- Source Pacing.
- Late Join.
- Off-Transport Recovery (OTR).
- Request/Response.
- Source-side Filtering.
- Hot Failover (HF).
- Message Properties.
- Application Headers.
- Implicit Batching and Explicit Batching.
- Message Fragmentation and Reassembly.
- Unicast Immediate Messaging.
- Multicast Immediate Messaging.
- The "pend"-style of Receiver thread behavior; SMX only supports busy_wait-style.
- Persistence.
- Queuing.
Note that while the use of Transport Services Provider (XSP) for network-based transports does not conflict with LBT-SMX, it does not apply to LBT-SMX. SMX data flows cannot be assigned to XSP threads.
You also cannot use LBT-SMX to send outgoing traffic from a UM daemon, such as the persistent Store, DRO, or UMDS.
LBT-SMX Configuration Example <-
The following diagram illustrates how sources and receivers interact with the shared memory area used in the LBT-SMX transport.
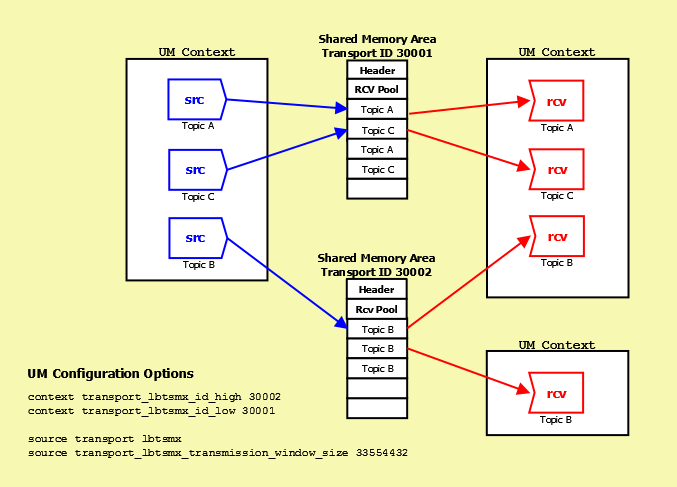
In the diagram above, three sources send (write) to two Shared Memory Areas while four receivers in two different contexts receive (read) from the areas. The assignment of sources to Shared Memory Areas demonstrate UM's round robin method. UM assigns the source sending on Topic A to Transport 30001, the source sending on Topic B to Transport 30002 and the source sending on Topic C back to the top of the transport ID range, 30001.
The diagram also shows the UM configuration options that set up this scenario.
- The options transport_lbtsmx_id_high (context) and transport_lbtsmx_id_low (context) establish the range of Transport IDs between 30001 and 30002.
- The option "source transport lbtsmx" sets the source's transport to LBT-SMX.
-
The option transport_lbtsmx_transmission_window_size (source) sets the size of each Shared Memory Area to 33554432 bytes or 32 MB. This option's value must be a power of 2. If you configured the transmission window size to 25165824 bytes (24 MB) for example, UM logs a warning message and then rounds the value of this option up to the next power of 2 or 33554432 bytes or 32 MB.
Java Coding for LBT-SMX <-
Java-based SMX works by wrapping the shared memory area in a ByteBuffer object. This lets the sender call the put methods to build your application message directly in the shared memory, and the receiver calls the get methods to extract the message directly from the shared memory.
Here are the SMX-specific APIs in Java:
- LBMSource.getMessagesBuffer() - obtains a reference to the source's ByteBuffer, which does not change for the lifetime of the source object.
- LBMSource.acquireMessageBufferPosition() - obtains an offset into the source's ByteBuffer for a new message of the specified length.
- LBMSource.messageBuffersComplete() - informs UM that one or more acquired messages are complete and ready to be delivered to receivers.
- LBMSource.messageBuffersCompleteAndAcquirePosition() - a convenience function that is the same as calling messageBuffersComplete() followed immediately by acquireMessageBufferPosition().
- LBMSource.messageBuffersCancel() - cancels all message buffers acquired but not yet completed.
Notice that while the normal source send can accept either a byte array or a ByteBuffer, the Java SMX-specific APIs only accept a ByteBuffer. Also note that the ByteBuffer does not necessarily start at position 0. You must call acquireMessageBufferPosition() to determine the offset.
The Java example programs Example lbmlatping.java and Example lbmlatpong.java illustrates how a Java-based SMX source and receiver is written.
For message reception, see the "onReceive" function. Note that there is no SMX-specific code. However, to maintain high performance, the user should call LBMSource.getMessagesBuffer() to obtain direct access to the source's ByteBuffer. The position and limit set according to the message to be read.
To save on some front-end latency, the "lat" ping/pong programs pre-acquire a buffer which is filled in when a messages needs to be sent (the call to src.acquireMessageBufferPosition()). After each send, another buffer is acquired for the next (future) message (the call to src.messageBuffersCompleteAndAcquirePosition()). This moves the overhead of acquiring a message buffer to after the message was sent.
Batching
SMX does not support the normal UM feature Implicit Batching. However, it does support a method of Intelligent Batching whereby multiple messages may be added to the source's ByteBuffer before being released to UM for delivery.
Note that unlike network-based transports, batching will give only minor benefits for SMX, mostly in the form of reduced memory contention.
Notice that the same ByteBuffer "buf" is used for both messages. This is because it is backed by the entire shared memory buffer. The current position of "buf" is set to the start of the message space acquired by acquireMessageBufferPosition().
Non-blocking
In the example code presented, calls to acquireMessageBufferPosition() passed zero for flags. This means that the call has the potential to block. Blocking happens if the sender outpaces the slowest receiver and the shared buffer fills. Because of receiver pacing, the source must not overwrite sent messages that have not been consumed by one or more subscribed receivers.
It is also possible to pass LBM.SRC_NONBLOCK as a flag to acquireMessageBufferPosition(). In that case, acquireMessageBufferPosition() will immediately return -1 if the shared buffer does not have enough space for the request.
For performance reasons, acquireMessageBufferPosition() does not throw LBMEWouldBlock exceptions, like the standard send APIs do.
Reduce Overhead
Normally, UM allows an application to add multiple receiver callbacks for the same topic receiver. This adds a small amount of overhead for a feature that is not used very often. This overhead can be eliminated by setting the "single receiver callback" attribute when creating the receiver object. This is done by calling LBMReceiverAttributes.enableSingleReceiverCallback().
.NET Coding for LBT-SMX <-
For most of UM functionality, the Java and .NET APIs are used almost identically. However, given SMX's latency requirements, we took advantage of some .NET capabilities that don't exist in Java, resulting in a different set of functions. In particular, instead of wrapping the shared memory area in a ByteBuffer, the .NET SMX API uses a simple IntPtr to provide a pointer directly into the shared memory area.
Here are the SMX-specific APIs in .NET:
- LBMSource.buffAcquire() - obtains a pointer into the source's shared buffer for a new message of the specified length.
- LBMSource.buffsComplete() - informs UM that one or more acquired messages are complete and ready to be delivered to receivers.
- LBMSource.buffsCompleteAndAcquire() - a convenience function that is the same as calling buffsComplete() followed immediately by acquireMessageBufferPosition().
- LBMSource.buffsCancel() - cancels all message buffers acquired but not yet completed.
- LBMMessage.dataPointerSafe() - Returns an IntPtr into the shared memory at the start of the message.
Notice that while the normal source send can accept either a byte array or a ByteBuffer, the .NET SMX-specific APIs only work with an IntPtr. This is because the application builds the message directly in the shared memory.
The .NET example programs Example lbmlatping.cs and Example lbmlatpong.cs illustrates how a .NET-based SMX source and receiver is written.
For message reception, see the "onReceive" function in Example lbmpong.cs. Note that there doesn't need to be any SMX-specific code. However, to maintain high performance, the user should call LBMMessage.dataPointerSafe() - to obtain direct access to the source's shared memory.
To save on some front-end latency, the "lat" ping/pong programs pre-acquire a buffer which is filled in when a messages needs to be sent (the call to source.buffAcquire()). After each send, another buffer is acquired for the next (future) message (the call to source.buffsCompleteAndAcquire()). This moves the overhead of acquiring a message buffer to after the message was sent.
Batching
SMX does not support the normal UM feature Implicit Batching. However, it does support a method of Intelligent Batching whereby multiple messages may be added to the source's shared memory before being released to UM for delivery.
Note that unlike network-based transports, batching will give only minor benefits for SMX, mostly in the form of reduced memory contention.
Non-blocking
In the example code presented, calls to buffAcquire() and buffsCompleteAndAcquire() are passed zero for flags. This means that the call has the potential to block. Blocking happens if the sender outpaces the slowest receiver and the shared buffer fills. Because of receiver pacing, the source must not overwrite sent messages that have not been consumed by one or more subscribed receivers.
It is also possible to pass LBM.SRC_NONBLOCK as a flag to buffAcquire(). In that case, buffAcquire() will immediately return -1 if the shared buffer does not have enough space for the request.
For performance reasons, buffsComplete() does not throw LBMEWouldBlock exceptions, like the standard send APIs do.
Reduce Overhead
Normally, UM allows an application to add multiple receiver callbacks for the same topic receiver. This adds a small amount of overhead for a feature that is not used very often. This overhead can be eliminated by setting the "single receiver callback" attribute when creating the receiver object. This is done by calling LBMReceiverAttributes.enableSingleReceiverCallback().
LBT-SMX Resource Manager <-
Deleting an SMX source or deleting an SMX receiver reclaims the shared memory area and locks allocated by the SMX source or receiver. However, if an ungraceful exit from a process occurs, global resources remain allocated but unused. To address this possibility, the LBT-SMX Resource Manager maintains a resource allocation database with a record for each global resource (memory or semaphore) allocated or freed. You can use the LBT-SMX Resource Manager to discover and reclaim resources. See the three example outputs below.
Displaying Resources
$> lbtsmx_resource_manager Displaying Resources (to reclaim you must type '-reclaim' exactly) --Memory Resources-- Memory resource: Process ID: 24441 SessionID: ab569cec XportID: 20001 --Semaphore Resources-- Semaphore key: 0x68871d75 Semaphore resource Index 0: reserved Semaphore resource: Process ID: 24441 Sem Index: 1 Semaphore resource: Process ID: 24436 Sem Index: 2
Reclaiming Unused Resources
- Warning
- This operation should never be done while SMX-enabled applications or daemons are running. If you have lost or unused resources that need to be reclaimed, you should exit all SMX applications prior to running this command.
$> lbtsmx_resource_manager -reclaim Reclaiming Resources Process 24441 not found: reclaiming Memory resource (SessionID: ab569cec XPortID: 20001) Process 24441 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 1 Process 24436 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 2
Transport Broker <-
With the UMQ product, you use the 'broker' transport to send messages from a source to a Queuing Broker, or from a Queuing Broker to a receiver.
The broker's Transport Pacing is receiver-paced, but only between the source and the broker. There is no end-to-end pacing with queuing.
When sources or receivers connect to a Queuing Broker, you must use the 'broker' transport. You cannot use the 'broker' transport with UMS or UMP products.