4. Architecture
UM is designed to be a flexible architecture. Unlike many messaging systems, UM does not require an intermediate daemon to handle routing issues or protocol processing. This increases the performance of UM and returns valuable computation time and memory back to applications that would normally be consumed by messaging daemons.
This section discusses the following topics.
4.1. Embedded Mode
When you create a context (lbm_context_create()) with the operational_mode set to embedded (the default), UM creates an independent thread, called the context thread, which handles timer and socket events, and does protocol-level processing, like retransmission of dropped packets.
4.2. Sequential Mode
When you create a context (lbm_context_create()) with the operational_mode set to sequential, the
context thread is NOT created. It becomes the application's responsibility to donate a
thread to UM by calling lbm_context_process_events() regularly, typically in a tight
loop. Use Sequential mode for circumstances where your application wants control over the
attributes of the context thread. For example, some applications raise the priority of
the context thread so as to obtain more consistent latencies. In sequential mode, no
separate thread is spawned when a context is created.
You enable Sequential mode with the following configuration option.
context operational_mode sequential
4.3. Topic Resolution
Topic resolution is the discovery of a topic's transport session information by a receiver to enable the receipt of topic messages. By default, UM relies on multicast requests and responses to resolve topics to transport sessions. (You can also use Unicast requests and responses, if needed.) UM receivers multicast their topic requests, or queries, to an IP multicast address and UDP port ( resolver_multicast_address and resolver_multicast_port). UM sources also multicast their advertisements and responses to receiver queries to the same multicast address and UDP port.
Topic Resolution offers 3 distinct phases that can be implemented.
-
Initial Phase - Period that allows you to resolve a topic aggressively. Can be used to resolve all known topics before message sending begins. This phase can be configured to run differently from the defaults or completely disabled.
-
Sustaining Phase - Period that allows new receivers to resolve a topic after the Initial Phase. Can also be the primary period of topic resolution if you disable the Initial Phase. This phase can also be configured to run differently from the defaults or completely disabled.
-
Quiescent Phase - The "steady state" period during which a topic is resolved and UM uses no system resources for topic resolution.
This section discusses the following topics.
4.3.1. Multicast Topic Resolution
The following diagram depicts the UM topic resolution using multicast.
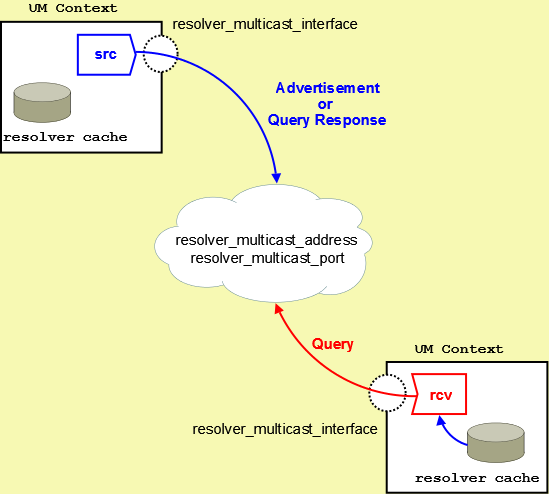
UM performs topic resolution automatically. Your application does not need to call any API functions to initiate topic resolution, however, you can influence topic resolution with Topic Resolution Configuration Options. Moreover, you can set configuration options for individual topics by using the lbm_*_attr_setopt() functions in your application. See Assigning Different Configuration Options to Individual Topics
Note: Multicast topic resolution traffic can use Datagram Bypass Layer (DBL) acceleration in conjunction with DBL-enabled Myricom® 10-Gigabit Ethernet NICs for Linux and Microsoft® Windows®. DBL is a kernel-bypass technology that accelerates sending and receiving UDP traffic. See Transport Acceleration Options for more information.
Note: Multicast Topic Resolution is not supported directly on the HP NonStop® platform, but can be run a different host within your network supplying topic resolution services to sources and receivers running on HP NonStop platform.
4.3.1.1. Sources Advertise
UM sources help UM receivers discover transport information in the following ways.
-
Advertise Active Topics - Each source advertises its active topic first upon its creation and subsequently according to the resolver_advertisement_*_interval configuration options for the Initial and Sustaining Phases. Sources advertise by sending a Topic Information Record (TIR). (You can prevent a source from sending an advertisement upon creation with resolver_send_initial_advertisement.)
-
Respond to Topic Queries - Each source responds immediately to queries from receivers about its topic.
Both a topic advertisement and a query response contain the topic's transport session information. Based on the transport type, a receiver can join the appropriate multicast group (for LBT-RM), send a connection request (for LBT-RU), connect to the source (for TCP) or access a shared memory area (for LBT-IPC). The address and port information potentially contained within a TIR includes:
-
For a TCP transport, the source address and TCP port.
-
For an LBT-RM transport, the unicast UDP port (to which NAKs are sent) and the UDP destination port.
-
For an LBT-RU transport, the source address and UDP port.
-
For an LBT-IPC transport, the Host ID, LBT-IPC Session ID and Transport ID.
-
For the UM Gateway, the context instance and Domain ID of the original source plus the Hop Count and Portal Cost. See Forwarding Costs
-
For various UMP options, the store address and TCP port, and the source address and TCP port (to which receivers send delivery confirmations).
-
For UMQ, the Queue Name, which allows the receiver to then resolve the Queue in order to receive queued messages.
4.3.1.2. Receivers Query
Receivers can discover transport information in the following ways.
-
Search advertisements collected in the resolver cache maintained by the UM context.
-
Listen for source advertisements on the resolver_multicast_address:port.
-
Send a topic query (TQR).
A new receiver queries for its topic according to the resolver_query_*_interval configuration options for the Initial and Sustaining Phases.
Note: The resolver_query_minimum_initial_interval actually begins after you call lbm_rcv_topic_lookup() prior to creating the receiver. If you have disabled the Initial Phase for the topic's resolution, the resolver_query_sustaining_interval begins after you call lbm_rcv_topic_lookup().
A Topic Query Record (TQR) consists primarily of the topic string. Receivers continue querying on a topic until they discover the number of sources configured by resolution_number_of_sources_query_threshold. However the large default of this configuration option (10,000,000) allows a receiver to continue to query until both the initial and sustaining phase of topic resolution complete.
4.3.1.3. Wildcard Receivers
Wildcard receivers can discover transport information in the following ways.
-
Search advertisements collected in the resolver cache maintained by the UM context.
-
Listen for source advertisements on the resolver_multicast_address:port.
-
Send a wildcard receiver topic query (WC-TQR).
UM implements only one phase of wildcard receiver queries, sending wildcard receiver queries according to wildcard receiver resolver_query_*_interval configuration options until the topic pattern has been queried for the resolver_query_minimum_duration. The wildcard receiver topic query (WC-TQR) contains the topic pattern and the pattern_type.
4.3.2. Topic Resolution Phases
The phases of topic resolution pertain to individual topics. Therefore if your system has 100 topics, 100 different topic resolution advertisement and query phases may be running concurrently. This describes the three phases of Ultra Messaging® topic resolution.
4.3.2.1. Initial Phase
The initial topic resolution phase for a topic is an aggressive phase that can be used to resolve all topics before sending any messages. During the initial phase, network traffic and CPU utilization might actually be higher. You can completely disable this phase, if desired. See Disabling Aspects of Topic Resolution.
4.3.2.1.1. Advertising in the Initial Phase
For the initial phase default settings, the resolver issues the first advertisement as soon as the scheduler can process it. The resolver issues the second advertisement 10 ms later, or at the resolver_advertisement_minimum_initial_interval. For each subsequent advertisement, UM doubles the interval between advertisements. The source sends an advertisement at 20 ms, 40 ms, 80 ms, 160 ms, 320 ms and finally at 500 ms, or the resolver_advertisement_maximum_initial_interval. These 8 advertisements require a total of 1130 ms. The interval between advertisements remains at the maximum 500 ms, resulting in 7 more advertisements before the total duration of the initial phase reaches 5000 ms, or the resolver_advertisement_minimum_initial_duration. This concludes the initial advertisement phase for the topic.
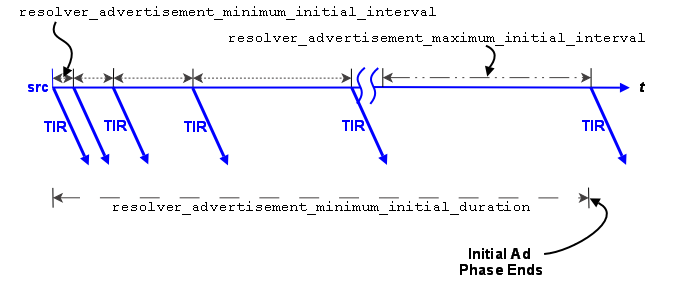
The initial phase for a topic can take longer than the resolver_advertisement_minimum_initial_duration if many topics are in resolution at the same time. The configuration options, resolver_initial_advertisements_per_second and resolver_initial_advertisement_bps enforce a rate limit on topic advertisements for the entire UM context. A large number of topics in resolution - in any phase - or long topic names may exceed these limits.
If a source advertising in the initial phase receives a topic query, it responds with a topic advertisement. UM recalculates the next advertisement interval from that point forward as if the advertisement was sent at the nearest interval.
4.3.2.1.2. Querying in the Initial Phase
Querying activity by receivers in the initial phase operates in similar fashion to advertising activity, although with different interval defaults. The resolver_query_minimum_initial_interval default is 20 ms. Subsequent intervals double in length until the interval reaches 200 ms, or the resolver_query_maximum_initial_interval. The query interval remains at 200 ms until the initial querying phase reaches 5000 ms, or the resolver_query_minimum_initial_duration.
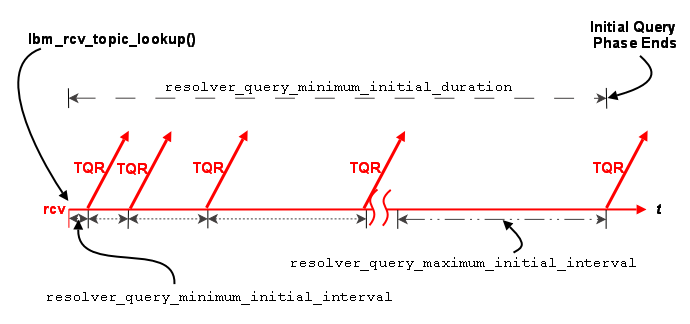
The initial query phase completes when it reaches the resolver_query_minimum_initial_duration. The initial query phase also has UM context-wide rate limit controls ( resolver_initial_queries_per_second and resolver_initial_query_bps) that can result in the extension of a phase's duration in the case of a large number of topics or long topic names.
4.3.2.2. Sustaining Phase
The sustaining topic resolution phase follows the initial phase and can be a less active phase in which a new receiver resolves its topic. It can also act as the sole topic resolution phase if you disable the initial phase. The sustaining phase defaults use less network resources than the initial phase and can also be modified or disabled completely. See Disabling Aspects of Topic Resolution.
4.3.2.2.1. Advertising in the Sustaining Phase
For the sustaining phase defaults, a source sends an advertisement every second ( resolver_advertisement_sustain_interval) for 1 minute ( resolver_advertisement_minimum_sustain_duration). When this duration expires, the sustaining phase of advertisement for a topic ends. If a source receives a topic query, the sustaining phase resumes for the topic and the source completes another duration of advertisements.
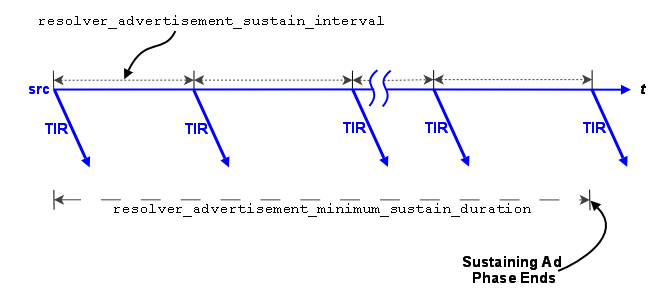
The sustaining advertisement phase has UM context-wide rate limit controls ( resolver_sustain_advertisements_per_second and resolver_sustain_advertisement_bps) that can result in the extension of a phase's duration in the case of a large number of topics or long topic names.
4.3.2.2.2. Querying in the Sustaining Phase
Default sustaining phase querying operates the same as advertising. Unresolved receivers query every second ( resolver_query_sustain_interval) for 1 minute ( resolver_query_minimum_sustain_duration). When this duration expires, the sustaining phase of querying for a topic ends.
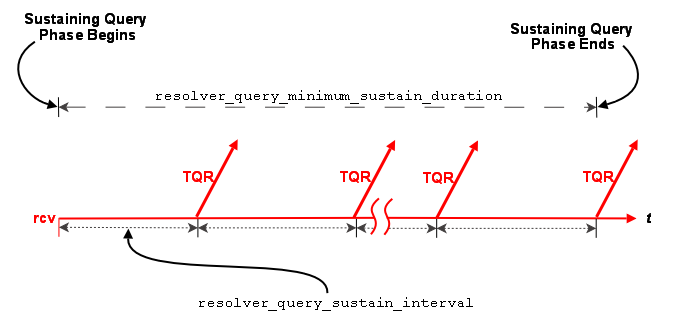
Sustaining phase queries stop when one of the following events occurs.
-
The receiver discovers multiple sources that equal resolution_number_of_sources_query_threshold.
-
The sustaining query phase reaches the resolver_query_minimum_sustain_duration.
The sustaining query phase also has UM context-wide rate limit controls ( resolver_sustain_queries_per_second and resolver_sustain_query_bps) that can result in the extension of a phase's duration in the case of a large number of topics or long topic names.
4.3.2.3. Quiescent Phase
This phase is the absence of topic resolution activity for a given topic. It is possible that some topics may be in the quiescent phase at the same time other topics are in initial or sustaining phases of topic resolution. This phase ends if either of the following occurs.
-
A new receiver sends a query.
-
Your application calls lbm_context_topic_resolution_request() that provokes the sending of topic queries for any receiver or wildcard receiver in this state.
4.3.3. Topic Resolution Configuration Options
Refer to the UM Configuration Guide for specific information about Topic Resolution Configuration Options.
4.3.3.1. Assigning Different Configuration Options to Individual Topics
You can assign different configuration option values to individual topics by accessing the topic attribute table (lbm_*_topic_attr_t_stct) before creating the source, receiver or wildcard receiver.
4.3.3.1.1. Creating a Source with Different Topic Resolution Options
-
Call lbm_src_topic_attr_setopt() to set new option value
-
Call lbm_src_topic_alloc()
-
Call lbm_src_create()
4.3.3.1.2. Creating a Receiver with Different Topic Resolution Options
-
Call lbm_rcv_topic_attr_setopt() to set new option value
-
Call lbm_rcv_topic_lookup()
-
Call lbm_rcv_create()
4.3.3.1.3. Creating a Wildcard Receiver with Different Topic Resolution Options
-
Call lbm_wildcard_rcv_attr_setopt() to set new wildcard receiver option value
-
Call lbm_wildcard_rcv_create()
4.3.3.2. Multicast Network Options
Essentially, the _incoming and _outgoing versions of resolver_multicast_address/port provide more fine-grained control of topic resolution. By default, the resolver_multicast_address and resolver_multicast_port and the _incoming and _outgoing address and port are set to the same value. If you want your context to listen to a particular multicast address/port and send on another address/port, then you can set the _incoming and _outgoing configuration options to different values.
4.3.4. Unicast Topic Resolution
This section also discusses the following topics.
By default UM expects multicast connectivity between all sources and receivers. When only unicast connectivity is available, you may configure all sources and receivers to use unicast topic resolution. This requires that you run one or more UM unicast topic resolution daemon(s) (Manpage for lbmrd), which perform the same topic resolution activities as multicast topic resolution. You configure each instance of the unicast topic resolution daemon with resolver_unicast_daemon.
Note: The Unicast Topic Resolver lbmrd is not supported on the HP NonStop platform.
The lbmrd can run on any machine, including the source or receiver (enter lbmrd -h for instructions). Of course, sources will also have to select a transport protocol that uses unicast addressing (e.g. TCP, TCP-LB, or LBT-RU). The lbmrd maintains a table of clients (address and port pairs) from which it has received a topic resolution message, which can be any of the following.
-
Topic Information Records (TIR) - also known as topic advertisements
-
Topic Query Records (TQR)
-
keepalive messages, which are only used in unicast topic resolution
After lbmrd receives a TQR or TIR, it forwards it to all known clients. If a client (i.e. source or receiver) is not sending either TIRs or TQRs, it sends a keepalive message to lbmrd according to the resolver_unicast_keepalive_interval. This registration with the lbmrd allows the client to receive advertisements or queries from lbmrd. lbmrd maintains no state about topics, only about clients.
4.3.4.1. Topic Information Records
Of all topic resolution messages, only the TIR contains address and port information. This tells a receiver how it can get the data being published. Based on the transport type, a receiver can join the appropriate multicast group (for LBT-RM), send a connection request (for LBT-RU), or connect to the source (for TCP).
The TIR contains additional blocks of information to define UMP capabilities, indicating the address and port of the source and store.
The address and port information potentially contained within a TIR includes:
-
For a TCP transport, the source address and TCP port.
-
For an LBT-RM transport, the unicast UDP port (to which NAKs are sent) and the UDP destination port.
-
For an LBT-RU transport, the source address and UDP port.
-
For various UMP options, the store address and TCP port, and the source address and TCP port (to which delivery confirmations are sent).
-
For UMQ, the Queue Name and TCP port.
For unicast-based transports (TCP and LBT-RU), the TIR source address is 0.0.0.0, not the actual source address. This allows some minimal functionality within a Network Address Translation (NAT) environment.
Topic resolution messages (whether received by the application via multicast, or by the unicast topic resolution daemon via unicast) are always UDP datagrams. They are received via a recvfrom() call, which also obtains the address and port from which the datagrams were received. If the address 0.0.0.0 (INADDR_ANY) appears for one of the addresses, lbmrd replaces it with the address from which the datagram is received. The net effect is as if the actual source address had originally been put into the TIR.
4.3.4.2. Unicast Topic Resolution Resilience
Running multiple instances of lbmrd allows your applications to continue operation in the face of a lbmrd failure. Your applications' sources and receivers send topic resolution messages as usual, however, rather than sending every message to each lbmrd instance, UM directs messages to lbmrd instances in a round-robin fashion. Since the lbmrd does not maintain any resolver state, as long as one lbmrd instance is running, UM continues to forward LBMR packets to all connected clients. UM switches to the next active lbmrd instance every 250-750 ms.
4.3.4.3. Unicast Topic Resolution Across Administrative Domains
If your network architecture includes remote or local LANs that use Network Address Translation (NAT), you can implement an lbmrd configuration file to translate IP addresses/ports across administrative domains. Without translation, lbmrd clients (sources and receivers) across NAT boundaries cannot connect to each other in response to topic advertisements due to NAT restrictions.
By default, topic advertisements forwarded by lbmrd contain the private (or inside) address/port of the source. Routers implementing NAT prevent connection to these private addresses from receivers outside the LAN.
The lbmrd configuration file allows lbmrd to insert a translation or outside address/port for the private address/port of the source in the topic advertisement. This outside or translation address must already be configured in the router's static NAT table. When the receiver attempts to connect to the source by using the source address/port in the topic advertisement, the NAT router automatically translates the outside address/port to the private address/port, thereby allowing the connection.
Note: The Request/Response model and the Late Join feature only work with (lbmrd) across local LANs that use Network Address Translation (NAT) if you use the default value (0.0.0.0) for request_tcp_interface.
4.3.4.3.1. lbmrd Configuration File
This section presents the syntax of the lbmrd configuration file, which is an XML file. Descriptions of elements also appear below. See Unicast Resolver Example Configuration for an example lbmrd configuration file.
<?xml version="1.0" encoding="UTF-8" ?>
<lbmrd version="1.0">
<domains>
<domain name="domain-name-1">
<network>network-specification</network>
</domain>
<domain name="domain-name-2">
<network>network-specification</network>
</domain>
</domains>
<transformations>
<transform source="source-domain-name"
destination="destination-domain-name">
<rule>
<match address="original-address" port="original-port"/>
<replace address="replacement-address" port="replacement-port"/>
</rule>
</transform>
</transformations>
</lbmrd>
4.3.4.3.1.1. <lbmrd> Element
The <lbmrd> element is the root element. It requires a single attribute, version, which defines the version of the DTD to be used. Currently, only version 1.0 is supported. The <lbmrd> element must contain a single <domains> element and a single <transformations> element.
4.3.4.3.1.2. <domains> Element
The <domains> element defines the set of network domains. The <domains> element may contain one or more <domain> elements. Each defines a separate domain.
4.3.4.3.1.3. <domain> Element
The <domain> element defines a single network domain. Each domain must be named via the name attribute. This name is referenced in <map> elements, which are discussed below. Each domain name must be unique. The <domain> element may contain one or more <network> elements.
4.3.4.3.1.4. <network> Element
The <network> element defines a single network specification which is to be considered part of the enclosing <domain>. The network specification must contain either an IP address, or a network specification in CIDR form.
4.3.4.3.1.5. <transformations> Element
The <transformations> element defines and contains the set of transformations to be applied to the TIRs. The <transformations> element contains one or more <transform> elements, described below.
4.3.4.3.1.6. <transform> Element
The <transform> element defines a set of transformation tuples. Each tuple applies to a TIR sent from a specific network domain (specified using the source attribute), and destined for a specific network domain (specified using the destination attribute). The source and destination attributes must specify a network domain name as defined by the <domain> elements. The <transform> element contains one or more <rule> elements, described below.
4.3.4.3.1.7. <rule> Element
Each <rule> element is associated with the enclosing <transform> element, and completes the transformation tuple. The <rule> element must contain one <match> element, and one <replace> element, described below.
4.3.4.3.1.8. <match> Element
The <match> element defines the address and port to match within the TIR. The attributes address and port specify the address and port. address must specify a full IP address (a network specification is not permitted). port specifies the port in the TIR. To match any port, specify port="*" (which is the default).
4.3.4.3.1.9. <replace> Element
The <replace> element defines the address and port which are to replace those matched in the TIR. The attributes address and port specify the address and port. address must specify a full IP address (a network specification is not permitted). To leave the TIR port unchanged, specify port="*" (which is the default).
4.3.4.3.1.10. Notes on the <match> and <replace> Elements
It is valid to specify port="*" for both <match> and <replace>. This effectively matches all ports for the given address and changes only the address. It is important to note that TIR addresses and ports are considered together. For example, the Ultra Messaging R for the Enterprise option in the TIR contains the source address and port, and the store address and port. When processing a transformation tuple, the source address and source port are considered (and transformed) together, and the store address and store port are considered (and transformed) together.
4.4. Message Batching
Batching many small messages into fewer network packets decreases the per-message CPU load, thereby increasing throughput. Let's say it costs 2 microseconds of CPU to fully process a message. If you process 10 messages per second, you won't notice the load. If you process half a million messages per second, you saturate the CPU. So to achieve high message rates, you have to reduce the per-message CPU cost with some form of message batching. These per-message costs apply to both the sender and the receiver. However, the implementation of batching is almost exclusively the realm of the sender.
Many people are under the impression that while batching improves CPU load, it increases message latency. While it is true that there are circumstances where this can happen, it is also true that careful use of batching can result in small latency increases or none at all. In fact, there are circumstances where batching can actually reduce latency.
UM allows the following methods for batching messages.
-
Implicit Batching - the default behavior, batching messages for individual transport sessions.
-
Adaptive Batching - a convenience feature of UM that monitors sending activity and automatically determines the optimum time to flush the Implicit Batch buffer.
-
Intelligent Batching - a method that makes use of your application's knowledge of the messages it must send, clearing the Implicit Batching buffer when sending the only remaining message.
-
Explicit Batching - provides greater control to your application through lbm_src_send() message flags and also operates in conjunction with the Implicit Batching mechanism.
-
Application Batching - your application groups messages and sends them in a single batch.
4.4.1. Implicit Batching
UM automatically batches smaller messages into transport session datagrams. The implicit batching options, implicit_batching_interval (default = 200 milliseconds) and implicit_batching_minimum_length (default = 2048 bytes) govern UM implicit message batching. Although these are source options, they actually apply to the transport session to which the source was assigned. See also Source Configuration and Transport Sessions.
UM establishes the implicit batching parameters when it creates the transport session. Any sources assigned to that transport session use the implicit batching limits set for that transport session, and the limits apply to any and all sources subsequently assigned to that transport session. This means that batched transport datagrams can contain messages on multiple topics. See Explicit Batching for information about topic-level message batching.
4.4.1.1. Implicit Batching Operation
Implicit Batching buffers messages until:
-
the buffer size exceeds the configured implicit_batching_minimum_length or
-
the oldest message in the buffer has been in the buffer for implicit_batching_interval milliseconds.
When either condition is met, UM flushes the buffer, pushing the messages onto the network.
It may appear this design introduces significant latencies for low-rate topics. However, remember that Implicit Batching operates on a transport session basis. Typically many low-rate topics map to the same transport session, providing a high aggregate rate. The implicit_batching_interval option is a last resort to prevent messages from becoming stuck in the Implicit Batching buffer. If your UM deployment frequently uses the implicit_batching_interval to push out the data (i.e. if the entire transport session has periods of inactivity longer than the value of implicit_batching_interval (defaults to 200 ms), then either the implicit batching options need to be fine-tuned (reducing one or both), or you should consider an alternate form of batching. See Intelligent Batching.
The minimum value for the implicit_batching_interval is 3 milliseconds. The actual minimum amount of time that data stays in the buffer depends on your Operating System and its scheduling clock interval. For example, on a Solaris 8 machine, the actual time is approximately 20 milliseconds. On Microsoft Windows machines, the time is probably 16 milliseconds. On a Linux 2.6 kernel, the actual time is 3 milliseconds. Using a implicit_batching_interval value of 3 guarantees the minimum possible wait for whichever operating system you are using.
4.4.1.2. Implicit Batching Example
The following example demonstrates how the implicit_batching_minimum_length is actually a trigger or floor, for sending batched messages. It is sometimes misconstrued as a ceiling or upper limit.
implicit_batching_minimum_length = 2000
-
The first send by your application puts 1900 bytes into the batching buffer, which is below the minimum, so UM holds it.
-
The second send fills the batching buffer to 3800 bytes, well over the minimum. UM sends it down to the transport layer, which builds a 3800-byte (plus overhead) datagram and sends it.
-
The Operating System fragments the datagram into packets independently of UM and reassembles them on the receiving end.
-
UM reads the datagram from the socket at the receiver.
-
UM parses out the two messages and delivers them to the appropriate topic levels, which deliver the data.
The proper setting of the implicit batching parameters often represents a tradeoff between latency and efficiency, where efficiency affects the highest throughput attainable. In general, a large minimum length setting increases efficiency and allows a higher peak message rate, but at low message rates a large minimum length can increase latency. A small minimum length can lower latency at low message rates, but does not allow the message rate to reach the same peak levels due to inefficiency. An intelligent use of implicit batching and application-level flushing can be used to implement an adaptive form of batching known as Intelligent Batching which can provide low latency and high throughput with a single setting.
4.4.2. Adaptive Batching
Adaptive Batching is a convenience batching feature that attempts to send messages
immediately during periods of low volume and automatically batch messages during periods
of higher volume. The goal of Adaptive Batching is to automatically optimize throughput
and latency by monitoring such things as the time between calls to lbm_src_send(), the time messages spend in the Implicit Batching
queue, the Rate Controller queue, and other sending activities. With this information,
Adaptive Batching determines if sending batched messages now or later produces the least
latency.
Adaptive Batching will not satisfy everyone's requirements of throughput and latency. You only need to turn it on and determine if it produces satisfactory performance. If it does, you need do nothing more. If you are not satisfied with the results, simply turn it off.
You enable Adaptive Batching by setting implicit_batching_type to adaptive. When using Adaptive Batching, it is advisable to increase the implicit_batching_minimum_length option to a higher value.
4.4.3. Intelligent Batching
Intelligent Batching uses Implicit Batching along with your application's knowledge of the messages it must send. It is a form of dynamic adaptive batching that automatically adjusts for different message rates. Intelligent Batching can provide significant savings of CPU resources without adding any noticeable latency.
For example, your application might receive input events in a batch, and therefore know that it must produce a corresponding batch of output messages. Or the message producer works off of an input queue, and it can detect messages in the queue.
In any case, if the application knows that it has more messages to send without going to sleep, it simply does normal sends to UM, letting Implicit Batching send only when the buffer meets the implicit_batching_minimum_length threshold. However, when the application detects that it has no more messages to send after it sends the current message, it sets the FLUSH flag (LBM_MSG_FLUSH) when sending the message which instructs UM to flush the implicit batching buffer immediately by sending all messages to the transport layer. Refer to lbm_src_send() in the UMS API documentation (UM C API, UM Java API or UM .NET API) for all the available send flags.
When using Intelligent Batching, it is usually advisable to increase the implicit_batching_minimum_length option to 10 times the size of the average message, to a maximum value of 8196. This tends to strike a good balance between batching length and flushing frequency, giving you low latencies across a wide variation of message rates.
4.4.4. Explicit Batching
UM allows you to batch messages for a particular topic with explicit batching. When your application sends a message (lbm_src_send()) it may flag the message as being the start of a batch (LBM_MSG_START_BATCH) or the end of a batch (LBM_MSG_END_BATCH). All messages sent between the start and end are grouped together. The flag used to indicate the end of a batch also signals UM to send the message immediately to the implicit batching buffer. At this point, Implicit Batching completes the batching operation. UM includes the start and end flags in the message so receivers can process the batched messages effectively.
Unlike Intelligent Batching which allows intermediate messages to trigger flushing according to the implicit_batching_minimum_length option, explicit batching holds all messages until the batch is completed. This feature is useful if you configure a relatively small implicit_batching_minimum_length and your application has a batch of messages to send that exceeds the implicit_batching_minimum_length. By releasing all the messages at once, Implicit Batching maximizes the size of the network datagrams.
4.4.4.1. Explicit Batching Example
The following example demonstrates explicit batching.
implicit_batching_minimum_length = 8000
-
Your application performs 10 sends of 100 bytes each as a single explicit batch.
-
At the 10th send (which completes the batch), UM delivers the 1000 bytes of messages to the implicit batch buffer.
-
Let's assume that the buffer already has 7899 bytes of data in it from other topics on the same transport session
-
UM adds the first 100-byte message to the buffer, bringing it to 7999.
-
UM adds the second 100-byte message, bringing it up to 8099 bytes, which exceeds implicit_batching_minimum_length but is below the 8192 maximum datagram size.
-
UM sends the 8099 bytes (plus overhead) datagram.
-
UM adds the third through tenth messages to the implicit batch buffer. These messages will be sent when either implicit_batching_minimum_length is again exceeded, or the implicit_batching_interval is met, or a message arrives in the buffer with the flush flag (LBM_MSG_FLUSH) set.
4.4.5. Application Batching
In all of the above situations, your application sends individual messages to UM and lets UM decide when to push the data onto the wire (often with application help). With application batching, your application buffers messages itself and sends a group of messages to UM with a single send. Thus, UM treats the send as a single message. On the receiving side, your application needs to know how to dissect the UM message into individual application messages.
This approach is most useful for Java or .NET applications where there is a higher per-message cost in delivering an UM message to the application. It can also be helpful when using an event queue to deliver received messages. This imposes a thread switch cost for each UM message. At low message rates, this extra overhead is not noticeable. However, at high message rates, application batching can significantly reduce CPU overhead.
4.5. Ordered Delivery
With the Ordered Delivery feature, a receiver's delivery controller can deliver messages to your application in sequence number order or arrival order. This feature can also reassemble fragmented messages or leave reassembly to the application. Ordered Delivery can be set via UM configuration option to one of three modes:
-
Sequence Number Order, Fragments Reassembled
-
Arrival Order, Fragments Not Reassembled
-
Arrival Order, Fragments Reassembled
4.5.1. Sequence Number Order, Fragments Reassembled (Default Mode)
In this mode, a receiver's delivery controller delivers messages in sequence number order (the same order in which they are sent). This feature also guarantees reassembly of fragmented large messages. To enable sequence number ordered delivery, set the ordered_delivery configuration option as shown:
receiver ordered_delivery 1
Please note that ordered delivery can introduce latency when packets are lost.
4.5.2. Arrival Order, Fragments Not Reassembled
This mode allows messages to be delivered to the application in the order they are received. If a message is lost, UM will retransmit the message. In the meantime, any subsequent messages received are delivered immediately to the application, followed by the dropped packet when its retransmission is received. This mode guarantees the lowest latency.
With this mode, the receiver delivers messages larger than the transport's maximum
datagram size as individual fragments. (See transport_*_datagram_max_size in the Ultra Messaging Configuration
Guide.) The C API function, lbm_msg_retrieve_fragment_info() returns fragmentation
information for the message you pass to it, and can be used to reassemble large messages.
(In Java and .NET, LBMMessage provides methods to return
the same fragment information.) Note that reassembly is not required for small
messages.
To enable this no-reassemble arrival-order mode, set the following configuration option as shown:
receiver ordered_delivery 0
When developing message reassembly code, consider the following:
-
Message fragments don't necessarily arrive in sequence number order.
-
Some message fragments may never arrive (unrecoverable loss), so you must time out partial messages.
4.5.3. Arrival Order, Fragments Reassembled
This mode delivers messages in the order they are received, except for fragmented messages, which UM reassembles before delivering to your application. Your application can then use the sequence_number field of lbm_msg_t objects to order or discard messages.
To enable this arrival-order-with-reassembly mode, set the following configuration option as shown:
receiver ordered_delivery -1
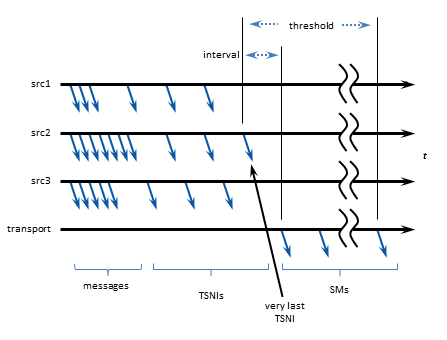
4.6. Loss Detection Using TSNIs
When a source enters a period during which it has no data traffic to send, that source issues timed Topic Sequence Number Info (TSNI) messages. The TSNI lets receivers know that the source is still active and also reminds receivers of the sequence number of the last message. This helps receivers become aware of any lost messages between TSNIs.
Sources send TSNIs over the same transport and on the same topic as normal data messages. You can set a time value of the TSNI interval with configuration option transport_topic_sequence_number_info_interval. You can also set a time value for the duration that the source sends contiguous TSNIs with configuration option transport_topic_sequence_number_info_active_threshold, after which time the source stops issuing TSNIs.
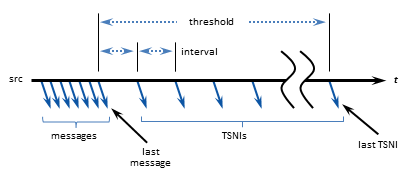
4.7. Receiver Keepalive Using Sesssion Messages
When an LBT-RM, LBT-RU, or LBT-IPC transport session enters a period during which it has no data traffic to send, UM issues timed Session Messages (SMs). For example, suppose all topics in a session stop sending data. One by one, they then send TSNIs, and if there is still no data to send, their TSNI periods eventually expire. After the last quiescent topic's TSNIs stop, UM begins transmitting SMs.
You can set time values for SM interval and duration with configuration options specific to their transport type.