3. UM Objects
Many UM documents use the term object. Be aware that with the C API, they do not refer to formal objects as supported by C++ (i.e. class instances). The term is used here in an informal sense to denote an entity that can be created, used, and (usually) deleted, has functionality and data associated with it, and is managed through the API. The handle that is used to refer to an object is usually implemented as a pointer to a data structure (defined in lbm.h), but the internal structure of an object is said to be opaque, meaning that application code should not read or write the structure directly.
However, the UM Java JNI and C# .NET APIs are object oriented, with formal Java/C# objects. See the Java documentation and .NET documentation for more information.
This section discusses the following objects.
3.1. Context Object
A UM context object conceptually is an environment in which UM runs. An application creates a context, typically during initialization, and uses it for most other UM operations. In the process of creating the context, UM normally starts an independent thread (the context thread) to do the necessary background processing such as the following.
-
Topic resolution
-
Enforce rate controls for sending messages
-
Manage timers
-
Manage state
-
Implement UM protocols
-
Manage transport sessions
You create a context with lbm_context_create(). Your
application can give a context a name with lbm_context_set_name(). Context names are optional but should be
unique. UM does not enforce uniqueness, rather issues a log
warning if it encounters duplicate context names. Each context maintains a cache of other
contexts it learns about through context advertisements, which UM sends according to resolver_context_advertisement_interval.
Context advertisement contains the context's name (if assigned), IP address, request port
( request_tcp_port) and a Context Instance ID - an internal value
assigned by UM. If a context needs to know about a context
that is not in its cache, it sends a context query, which the "unknown" context replies
to with a context advertisement. This mechanism for naming and advertising UM contexts facilitates UM Gateway operation especially for UMP .
One of the more important functions of a context is to hold configuration information that is of context scope. See the UM Configuration Guide for options that are of context scope.
Most UM applications create a single context. However, there are some specialized circumstances where an application would create multiple contexts. For example, with appropriate configuration options, two contexts can provide separate topic name spaces. Also, multiple contexts can be used to portion available bandwidth across topic sub-spaces (in effect allocating more bandwidth to high-priority topics).
Warning Regardless of the number of contexts created by your application, a good practice is to keep them open throughout the life of your application. Do not close them until you close the application.
3.2. Topic Object
A UM topic object is conceptually very simple; it is little more than a string (the topic name). However, UM uses the topic object to hold a variety of state information used by UM for internal processing. It is conceptually contained within a context. Topic objects must be bound to source or receiver objects.
A data source creates a topic by calling lbm_src_topic_alloc(). A data receiver doesn't explicitly create
topic objects; UM does that as topics are discovered and
cached. Instead, the receiving application calls lbm_rcv_topic_lookup() to find the topic object.
Unlike other objects, the topic object is not created or deleted by the application.
UM creates, manages and deletes them internally as needed.
However, the application does use them, so the API has functions that give the
application access to them when needed (lbm_src_topic_alloc() and lbm_rcv_topic_lookup()).
3.3. Source Object
A UM source object is used to send messages to the topic that it is bound to. It is conceptually contained within a context.
You create a source object by calling lbm_src_create().
One of its parameters is a topic object that must have been previously allocated. A
source object can be bound to only one topic. (A topic object, however, can be bound to
many sources provided the sources exist in separate contexts.)
3.3.1. Message Properties Object
The message properties object allows your application to insert named, typed metadata in topic messages, and to implement functionality that depends on the message properties. UM allows eight property types: boolean, byte, short, int, long, float, double, and string.
To use message properties, create a message properties object with lbm_msg_properties_create(). Then send topic messages with lbm_src_send_ex() (or LBMSource.send() in the Java API or .NET
API) passing the message properties object through lbm_src_send_ex_info_t object. Set the
LBM_SRC_SEND_EX_FLAG_PROPERTIES flag on the lbm_src_send_ex_info_t object to indicate that it includes
properties.
Upon a receipt of a message with properties, your application can access the properties directly through the messages properties field, which is null if no properties are present. You can retrieve individual property values directly by name, or you can iterate over the collection of properties to determine which properties are present at runtime.
The UM message property object supports the standard JMS message properties specification.
Note: The Message Properties Object does not support receivers using the arrival order without reassembly setting (option value = 0) of ordered_delivery.
3.3.1.1. Message Properties Performance Considerations
UM sends property names on the wire with every message. To reduce bandwidth requirements, minimize the length and number of properties.
When coding sources, consider the following sequence of guidelines:
-
Allocate a data structure to store message properties objects. This can be a thread-local structure if you use a relatively small number of threads, or a thread-safe pool of objects.
-
Before sending, retrieve a message properties object from the pool. If an object is not available, create a new object.
-
Set properties for the message.
-
Send the message using the appropriate API call, passing in the properties object.
-
After the send completes, clear the message properties object and return it to the pool.
When coding receivers in Java or .NET, call Dispose() on messages before returning from the application callback. This allows UM to internally recycle objects, and limits object allocation.
3.3.2. Source Configuration and Transport Sessions
As with contexts, a source holds configuration information that is of source scope. This includes network options, operational options and reliability options for LBT-RU and LBT-RM. For example, each source can use a different transport and would therefore configure a different network address to which to send topic messages. See the UM Configuration Guide for source configuration options.
As stated in Transports, many topics (and therefore sources) can be mapped to a single transport. Many of the configuration options for sources actually control or influence transport session activity. If many sources are sending topic messages over a single transport session (TCP, LBT-RU or LBT-RM), UM only uses the configuration options for the first source assigned to the transport.
For example, if the first source to use a LBT-RM transport session sets the transport_lbtrm_transmission_window_size to 24 MB and the second source sets the same option to 2 MB, UMS assigns 24 MB to the transport session's transport_lbtrm_transmission_window_size.
The UM Configuration Guide identifies the source configuration options that may be ignored when UM assigns the source to an existing transport session. Log file warnings also appear when UM ignores source configuration options.
3.3.3. Zero Object Delivery (Source)
The Zero Object Delivery (ZOD) feature for Java and .NET lets sources deliver events to an application with no per-event object creation. (ZOD can also be utilized with context source events.) See Zero Object Delivery (ZOD) for information on how to employ ZOD.
3.4. Receiver Object
A UM receiver object is used to receive messages from the topic that it is bound to. It is conceptually contained within a context. Messages are delivered to the application by an application callback function, specified when the receiver object is created.
You create a receiver object by calling lbm_rcv_create(). One of its parameters is a topic object that
must have been previously looked up. A receiver object can be bound to only one topic.
Multiple receiver objects can be created for the same topic.
3.4.1. Receiver Configuration and Transport Sessions
A receiver holds configuration information that is of receiver scope. This includes network options, operational options and reliability options for LBT-RU and LBT-RM. See the UM Configuration Guide for receiver configuration options.
As stated above in Source Configuration and Transport Sessions, many topics (and therefore receivers) can be mapped to a single transport. As with source configuration options, many receiver configuration options control or influence transport session activity. If many receivers are receiving topic messages over a single transport session (TCP, LBT-RU or LBT-RM), UM only uses the configuration options for the first receiver assigned to the transport.
For example, if the first receiver to use a LBT-RM transport session sets the transport_lbtrm_nak_generation_interval to 10 seconds and the second receiver sets the same option to 2 seconds, UMS assigns 10 seconds to the transport session's transport_lbtrm_nak_generation_interval.
The UM Configuration Guide identifies the receiver configuration options that may be ignored when UM assigns the receiver to an existing transport session. Log file warnings also appear when UM ignores receiver configuration options.
3.4.2. Wildcard Receiver
A wildcard receiver object is created by calling lbm_wildcard_rcv_create(). Instead of a topic object, the caller
supplies a pattern which is used by UM to match multiple
topics. Since the application doesn't explicitly lookup the topics, the topic attribute
is passed into lbm_wildcard_rcv_create() so that options
can be set. Also, wildcarding has its own set of options (e.g. pattern type).
The pattern supplied for wildcard matching is normally a general regular expression.
There are two types of supported regular expressions that differ somewhat in the syntax
of the patterns (see the wildcard_receiver pattern_type
option in the UM
Configuration Guide). Those types are:
-
PCRE- (recommended) the same form of regular expressions recognized by Perl; see http://perldoc.perl.org/perlrequick.html for details, or -
regex- POSIX extended regular expressions; see http://www.freebsd.org/cgi/man.cgi?query=re_format§ion=7 for details. Note thatregexis not supported on all platforms.
A third type of wildcarding is appcb, in which the
application defines its own algorithm to select topic names. When appcb is configured, the pattern
parameter of lbm_wildcard_rcv_create() is ignored. Instead,
an application callback function is configured (see the wildcard_receiver pattern_callback option in the UM Configuration
Guide). UM then calls that application function with a
topic name and the function can use whatever method is appropriate to decide if the topic
should be included with the receiver.
Be aware that some platforms may not support all of the regular expression wildcard
types. For example, UM does not support the use of Unicode
PCRE characters in wildcard receiver patterns on any system that communicates with a
HP-UX or AIX system. See the UM Knowledgebase article, Platform-Specific Dependencies for details. Also note that if UM topic resolution is configured to turn off source
advertisements, then wildcard receivers must be configured for PCRE.
The other wildcard types do not support receiver queries for topic resolution.
For an example of wildcard usage, see lbmwrcv.c
Users of TIBCO® SmartSockets™ will want to look at the UM Knowledgebase article, Wildcard Topic Regular Expressions.
3.4.3. Zero Object Delivery (ZOD)
The Zero Object Delivery (ZOD) feature for Java and .NET lets receivers (and sources) deliver messages and events to an application with no per-message or per-event object creation. This facilitates source/receiver applications that would require little to no garbage collection at runtime, producing lower and more consistent message latencies.
To take advantage of this feature, you must call dispose() on a message to mark it as available for reuse. To
access data from the message when using ZOD, you use a specific pair of LBMMessage-class
methods (see below) to extract message data directly from the message, rather than the
standard data() method. Using the latter method creates a
byte array, and consequently, an object. It is the subsequent garbage collecting to
recycle those objects that can affect performance.
For using ZOD, the LBMMessage class methods are:
-
Java:
dispose(),dataBuffer(), anddataLength() -
.NET:
dispose(),dataPointer(), andlength()
On the other hand, you may need to keep the message as an object for further use after
callback. In this case, ZOD is not appropriate and you must call promote() on the message, and also you can use data() to extract message data.
For more details see the Java API Overview or the .Net LBMMessage Class description. This feature does not apply to the C API.
3.5. Event Queue Object
A UM event queue object is conceptually a managed data and control buffer. UM delivers events (including received messages) to your application by means of application callback functions. Without event queues, these callback functions are called from the UM context thread, which places the following restrictions on the application function being called:
-
The application function is not allowed to make certain API calls (mostly having to do with creating or deleting UM objects).
-
The application function must execute very quickly without blocking.
-
The application does not have control over when the callback executes. It can't prevent callbacks during critical sections of application code.
Some circumstances require the use of UM event queues. As mentioned above, if the receive callback needs to use UM functions that create or delete objects. Or if the receive callback performs operations that potentially block. You may also want to use an event queue if the receive callback is CPU intensive and can make good use of multiple CPU hardware. Not using an event queue provides the lowest latency, however, high message rates or extensive message processing can negate the low latency benefit if the context thread continually blocks.
Of course, your application can create its own queues, which can be bounded, blocking queues or unbounded, non-blocking queues. For transports that are flow-controlled, a bounded, blocking application queue preserves flow control in your messaging layer because the effect of a filled or blocked queue extends through the message path all the way to source. The speed of the application queue becomes the speed of the source.
UM event queues are unbounded, non-blocking queues and provide the following unique features.
-
Your application can set a queue size threshold with queue_size_warning and be warned when the queue contains too many messages.
-
Your application can set a delay threshold with queue_delay_warning and be warned when events have been in the queue for too long.
-
The application callback function has no UM API restrictions.
-
Your application can control exactly when UM delivers queued events with
lbm_event_dispatch(). And you can have control return to your application either when specifically asked to do so (by callinglbm_event_dispatch_unblock()), or optionally when there are no events left to deliver. -
Your application can take advantage of parallel processing on multiple processor hardware since UM processes asynchronously on a separate thread from your application's processing of received messages. By using multiple application threads to dispatch an event queue, or by using multiple event queues, each with its own dispatch thread, your application can further increase parallelism.
You create an UM event queue in the C API by calling lbm_event_queue_create(). In the Java API and the .NET API, use the LBMEventQueue class. An event queue object also holds configuration
information that is of event queue scope. See Event Queue Options.
3.6. Transport Objects
This section discusses the following topics.
3.6.1. Transport TCP
The TCP UMS transport uses normal TCP connections to send messages from sources to receivers. This is the default transport when it's not explicitly set. TCP is a good choice when:
-
Flow control is desired. I.e. when one or more receivers cannot keep up, it is desired to slow down the source. This is a "better late than never" philosophy.
-
Equal bandwidth sharing with other TCP traffic is desired. I.e. when it is desired that the source slow down when general network traffic becomes heavy.
-
There are few receivers listening to each topic. Multiple receivers for a topic requires multiple transmissions of each message, which places a scaling burden on the source machine and the network.
-
The application is not sensitive to latency. Use of TCP as a messaging transport can result in unbounded latency.
-
The messages must pass through a restrictive firewall which does not pass multicast traffic.
Note: TCP transports may be distributed to receiving threads. See Multi-Transport Threads for more information.
3.6.2. Transport TCP-LB
The TCP-LB UMS transport is a variation on the TCP transport which adds latency-bounded behavior. The source is not flow-controlled as a result of network congestion or slow receivers. So, for applications that require a "better never than late" philosophy, TCP-LB can be a better choice.
However, latency cannot be controlled as tightly as with UDP-based transports (see below). In particular, latency can still be introduced because TCP-LB shares bandwidth equally with other TCP traffic. It also has the same scaling issues as TCP when multiple receivers are present for each topic.
Note: TCP-LB transports may be distributed to receiving threads. See Multi-Transport Threads for more information.
3.6.3. Transport LBT-RU
The LBT-RU UMS transport adds reliable delivery to unicast UDP to send messages from sources to receivers. This provides greater flexibility in the control of latency. For example, the application can further limit latency by allowing the use of arrival order delivery. See the UM Knowledgebase FAQ, Why can't I have low-latency delivery and in-order delivery?. Also, LBT-RU is less sensitive to overall network load; it uses source rate controls to limit its maximum send rate.
Since it is based on unicast addressing, LBT-RU can pass through most firewalls. However, it has the same scaling issues as TCP when multiple receivers are present for each topic.
Note: LBT-RU can use Datagram Bypass Layer (DBL) acceleration in conjunction with DBL-enabled Myricom® 10-Gigabit Ethernet NICs for Linux and Microsoft® Windows®. DBL is a kernel-bypass technology that accelerates sending and receiving UDP traffic. See Transport Acceleration Options for more information.
Note: LBT-RU transports may be distributed to receiving threads. See Multi-Transport Threads for more information.
3.6.4. Transport LBT-RM
The LBT-RM UMS transport adds reliable multicast to UDP to send messages. This provides the maximum flexibility in the control of latency. In addition, LBT-RM can scale effectively to large numbers of receivers per topic using network hardware to duplicate messages only when necessary at wire speed. One limitation is that multicast is often blocked by firewalls.
LBT-RM is a UDP-based, reliable multicast protocol designed with the use of UM and its target applications specifically in mind. The protocol is very similar to PGM, but with changes to aid low latency messaging applications.
-
Topic Mapping - Several topics may map onto the same LBT-RM session. Thus a multiplexing mechanism to LBT-RM is used to distinguish topic level concerns from LBT-RM session level concerns (such as retransmissions, etc.). Each message to a topic is given a sequence number in addition to the sequence number used at the LBT-RM session level for packet retransmission.
-
Negative Acknowledgments (NAKs) - LBT-RM uses NAKs as PGM does. NAKs are unicast to the sender. For simplicity, LBT-RM uses a similar NAK state management approach as PGM specifies.
-
Time Bounded Recovery - LBT-RM allows receivers to specify a a maximum time to wait for a lost piece of data to be retransmitted. This allows a recovery time bound to be placed on data that has a definite lifetime of usefulness. If this time limit is exceeded and no retransmission has been seen, then the piece of data is marked as an unrecoverable loss and the application is informed. The data stream may continue and the unrecoverable loss will be ordered as a discrete event in the data stream just as a normal piece of data.
-
Flexible Delivery Ordering - LBT-RM receivers have the option to have the data for an individual topic delivered "in order" or "arrival order". Messages delivered "in order" will arrive in sequence number order to the application. Thus loss may delay messages from being delivered until the loss is recovered or unrecoverable loss is determined. With "arrival-order" delivery, messages will arrive at the application as they are received by the LBT-RM session. Duplicates are ignored and lost messages will have the same recovery methods applied, but the ordering may not be preserved. Delivery order is a topic level concern. Thus loss of messages in one topic will not interfere or delay delivery of messages in another topic.
-
Session State Advertisements - In PGM, SPM packets are used to advertise session state and to perform PGM router assist in the routers. For LBT-RM, these advertisements are only used when data is not flowing. Once data stops on a session, advertisements are sent with an exponential back-off (to a configurable maximum interval) so that the bandwidth taken up by the session is minimal.
-
Sender Rate Control - LBT-RM can control a sender's rate of injection of data into the network by use of a rate limiter. This rate is configurable and will back pressure the sender, not allowing the application to exceed the rate limit it has specified. In addition, LBT-RM senders have control over the rate of retransmissions separately from new data. This allows sending application to guarantee a minimum transmission rate even in the face of massive loss at some or all receivers.
-
Low Latency Retransmissions - LBT-RM senders do not mandate the use of NCF packets as PGM does. Because low latency retransmissions is such an important feature, LBT-RM senders by default send retransmissions immediately upon receiving a NAK. After sending a retransmission, the sender ignores additional NAKs for the same data and does not repeatedly send NCFs. The oldest data being requested in NAKs has priority over newer data so that if retransmissions are rate controlled, then LBT-RM sends the most important retransmissions as fast as possible.
Note: LBT-RM can use Datagram Bypass Layer (DBL) acceleration in conjunction with DBL-enabled Myricom 10-Gigabit Ethernet NICs for Linux and Microsoft Windows. DBL is a kernel-bypass technology that accelerates sending and receiving UDP traffic. See Transport Acceleration Options for more information.
Note: LBT-RM transports may be distributed to receiving threads. See Multi-Transport Threads for more information.
3.6.5. Transport LBT-IPC
The LBT-IPC transport is an Interprocess Communication (IPC) UM transport that allows sources to publish topic messages to a shared memory area managed as a static ring buffer from which receivers can read topic messages. Message exchange takes place at memory access speed which can greatly improve throughput when sources and receivers can reside on the same host. LBT-IPC can be either source-paced or receiver-paced.
The LBT-IPC transport uses a "lock free" design that eliminates calls to the Operating System and allows receivers quicker access to messages. An internal validation method enacted by receivers while reading messages from the Shared Memory Area ensures message data integrity. The validation method compares IPC header information at different times to ensure consistent, and therefore, valid message data. Sources can send individual messages or a batch of messages, each of which possesses an IPC header.
Note: Transport LBT-IPC is not supported on the HP NonStop® platform.
3.6.5.1. LBT-IPC Shared Memory Area
The following diagram illustrates the Shared Memory Area used for LBT-IPC.
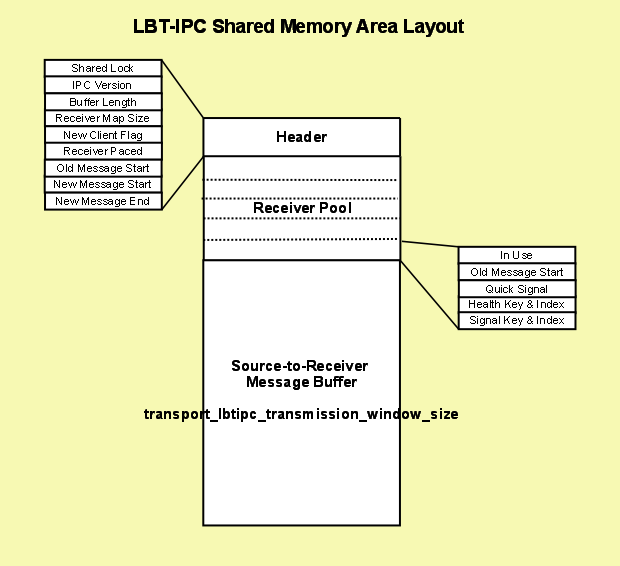
3.6.5.1.1. Header
The Header contains information about the shared memory area resource.
-
Shared Lock - shared receiver pool semaphore (mutex on Microsoft Windows) to ensure mutually exclusive access to the receiver pool.
-
Version - LBT-IPC version number which is independent of any UM product version number.
-
Buffer Length - size of shared memory area.
-
Receiver Map Size - Number of entries available in the Receiver Pool which you configure with the source option, transport_lbtipc_maximum_receivers_per_transport.
-
New Client Flag - set by the receiver after setting its Receiver Pool entry and before releasing the Shared Lock. Indicates to the source that a new receiver has joined the transport.
-
Receiver Paced - Indicates if you've configured the transport for receiver-pacing.
-
Old Message Start - pointer indicating messages that may be reclaimed.
-
New Message Start - pointer indicating messages that may be read.
-
New Message End - pointer indicating the end of messages that may be read, which may not be the same as the Old Message Start pointer.
3.6.5.1.2. Receiver Pool
The receiver pool is a collection of receiver connections maintained in the Shared Memory Area. The source reads this information if you've configured receiver-pacing to determine if a message can be reclaimed or to monitor a receiver. Each receiver is responsible for finding a free entry in the pool and marking it as used.
-
In Use flag - set by receiver while holding the Shared Lock, which effectively indicates the receiver has joined the transport session. Using the Shared Lock ensures mutually exclusive access to the receiver connection pool.
-
Oldest Message Start - set by receiver after reading a message. If you enable receiver-pacing the source reads it to determine if message memory can be reclaimed.
-
Monitor Shared Lock - checked by the source to monitor a receiver. (semaphore on Linux, event on Microsoft Windows) See Receiver Monitoring.
-
Signal Shared Lock - Set by source to notify receiver that new data has been written. (semaphore on Linux, mutex on Microsoft Windows) If you set transport_lbtipc_receiver_thread_behavior to busy_wait, the receiver sets this semaphore to zero and the source does not notify.
3.6.5.1.3. Source-to-Receiver Message Buffer
This area contains message data. You specify the size of the shared memory area with a source option, transport_lbtipc_transmission_window_size. The size of the shared memory area cannot exceed your platform's shared memory area maximum size. UM stores the memory size in the shared memory area's header. The Old Message Start and New Message Start point to positions in this buffer.
3.6.5.2. Sources and LBT-IPC
When you create a source with lbm_src_create() and you've set the transport option to IPC, UM creates a shared memory area object. UM assigns one of the transport IDs to this area specified with the UM context configuration options, transport_lbtipc_id_high and transport_lbtipc_id_low. You can also specify a shared memory location outside of this range with a source configuration option, transport_lbtipc_id, to prioritize certain topics, if needed.
UM names the shared memory area object according to the format, LBTIPC_%x_%d where %x is the hexadecimal Session ID and %d is the decimal Transport ID. Examples names are LBTIPC_42792ac_20000 or LBTIPC_66e7c8f6_20001. Receivers access a shared memory area with this object name to receive (read) topic messages.
Using the configuration option, transport_lbtipc_behavior, you can choose source-paced or receiver-paced message transport. See Transport LBT-IPC Operation Options.
3.6.5.2.1. Sending over LBT-IPC
To send on a topic (write to the shared memory area) the source writes to the Shared Memory Area starting at the Oldest Message Start position. It then increments each receiver's Signal Lock if the receiver has not set this to zero.
3.6.5.3. Receivers and LBT-IPC
Receivers operate identically to receivers for all other UM transports. A receiver can actually receive topic messages from a source sending on its topic over TCP, LBT-RU or LBT-RM and from a second source sending on LBT-IPC with out any special configuration. The receiver learns what it needs to join the LBT-IPC session through the topic advertisement.
3.6.5.3.1. Topic Resolution and LBT-IPC
Topic resolution operates identically with LBT-IPC as other UM transports albeit with a new advertisement type, LBMIPC. Advertisements for LBT-IPC contain the Transport ID, Session ID and Host ID. Receivers obtain LBT-IPC advertisements in the normal manner (resolver cache, advertisements received on the multicast resolver address:port and responses to queries.) Advertisements for topics from LBT-IPC sources can reach receivers on different machines if they use the same topic resolution configuration, however, those receivers silently ignore those advertisements since they cannot join the IPC transport. See Sending to Both Local and Remote Receivers.
3.6.5.3.2. Receiver Pacing
Although receiver pacing is a source behavior option, some different things must happen on the receiving side to ensure that a source does not reclaim (overwrite) a message until all receivers have read it. When you use the default transport_lbtipc_behavior (source-paced), each receiver's Oldest Message Start position in the Shared Memory Area is private to each receiver. The source writes to the Shared Memory Area independently of receivers' reading. For receiver-pacing, however, all receivers share their Oldest Message Start position with the source. The source will not reclaim a message until all receivers have successfully read that message.
3.6.5.3.3. Receiver Monitoring
To ensure that a source does not wait on a receiver that is not running, the source monitors a receiver via the Monitor Shared Lock allocated to each receiving context. (This lock is in addition to the semaphore already allocated for signaling new data.) A new receiver takes and holds the Monitor Shared Lock and releases the resource when it dies. If the source is able to obtain the resource, it knows the receiver has died. The source then clears the receiver's In Use flag in it's Receiver Pool Connection.
3.6.5.4. Similarities with Other UM Transports
Although no actual network transport occurs, UM functions in much the same way as if you send packets across the network as with other UM transports.
-
If you use a range of LBT-IPC transport IDs, UM assigns multiple topics sent by multiple sources to all the transport sessions in a round robin manner just like other UM transports.
-
Transport sessions assume the configuration option values of the first source assigned to the transport session.
-
Sources are subject to message batching.
3.6.5.5. Differences from Other UM Transports
-
Unlike LBT-RM which uses a transmission window to specify a buffer size to retain messages in case they must be retransmitted, LBT-IPC uses the transmission window option to establish the size of the shared memory.
-
LBT-IPC does not retransmit messages. Since LBT-IPC transport is essentially a memory write/read operation, messages should not be be lost in transit. However, if the shared memory area fills up, new messages overwrite old messages and the loss is absolute. No retransmission of old messages that have been overwritten occurs.
-
Receivers also do not send NAKs when using LBT-IPC.
-
LBT-IPC does not support Ordered Delivery options. However, if you set ordered_delivery 1 or -1, LBT-IPC reassembles any large messages.
-
LBT-IPC does not support Rate Control.
-
LBT-IPC creates a separate receiver thread in the receiving context.
3.6.5.6. Sending to Both Local and Remote Receivers
A source application that wants to support both local and remote receivers should create two UM Contexts with different topic resolution configurations, one for IPC sends and one for sends to remote receivers. Separate contexts allows you to use the same topic for both IPC and network sources. If you simply created two source objects (one IPC, one say LBT-RM) in the same UM Context, you would have to use separate topics and suffer possible higher latency because the sending thread would be blocked for the duration of two send calls.
A UM source will never automatically use IPC when the receivers are local and a network transport for remote receivers because the discovery of a remote receiver would hurt the performance of local receivers. An application that wants transparent switching can implement it in a simple wrapper.
3.6.5.7. LBT-IPC Object Diagram
The following diagram illustrates how sources and receivers interact with the shared memory area used in the LBT-IPC transport.
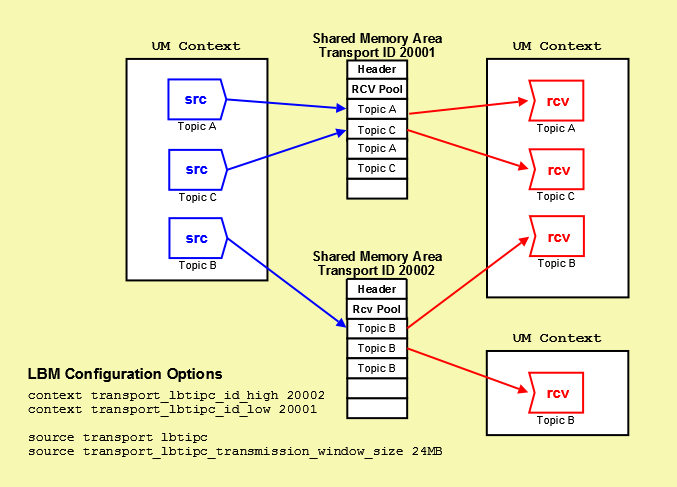
In the diagram above, 3 sources send (write) to two Shared Memory Areas while four receivers in two different contexts receive (read) from the areas. The diagram also shows the UM configuration options that set up this scenario. The assignment of sources to Shared Memory Areas demonstrate UM's round robin method. UM assigns the source sending on Topic A to Transport 20001, the source sending on Topic B to Transport 20002 and the source sending on Topic C back to the top of the transport ID range, 20001. The memory area size, although the default value, appears for illustration.
3.6.5.8. Required Authorities
LBT-IPC requires no special operating system authorities, except on Microsoft Windows Vista® and Microsoft Windows Server 2008, which require Administrator privileges. In addition, on Microsoft Windows XP, applications must be started by the same user, however, the user is not required to have administrator privileges. In order for applications to communicate with a service, the service must use a user account that has Administrator privileges.
3.6.5.9. Host Resource Usage and Limits
LBT-IPC contexts and sources consume host resources as follows.
-
Per Source - 1 shared memory segment, 1 shared lock (semaphore on Linux, mutex on Microsoft Windows)
-
Per Receiving Context - 2 shared locks (semaphores on Linux, one event and one mutex on Microsoft Windows)
Across most operating system platforms, these resources have the following limits.
-
4096 shared memory segments, though some platforms use different limits
-
32,000 shared semaphores (128 shared semaphore sets * 250 semaphores per set)
Consult your operating system documentation for specific limits per type of resource. Resources may be displayed and reclaimed using the LBT-IPC Resource Manager. See also Managing LBT-IPC Host Resources.
3.6.5.10. LBT-IPC Resource Manager
Deleting an IPC source with lbm_src_delete() or deleting an IPC receiver with lbm_rcv_delete() reclaims the shared memory area and locks allocated by the IPC source or receiver. However, if a less than graceful exit from a process occurs, global resources remain allocated but unused. To address this possibility, the LBT-IPC Resource Manager maintains a resource allocation database with a record for each global resource (memory or semaphore) allocated or freed. You can use the LBT-IPC Resource Manager to discover and reclaim resources. See the three example outputs below.
3.6.5.10.1. Displaying Resources
$> lbtipc_resource_manager
Displaying Resources (to reclaim you must type '-reclaim' exactly)
--Memory Resources--
Memory resource: Process ID: 24441 SessionID: ab569cec XportID: 20001
--Semaphore Resources--
Semaphore key: 0x68871d75
Semaphore resource Index 0: reserved
Semaphore resource: Process ID: 24441 Sem Index: 1
Semaphore resource: Process ID: 24436 Sem Index: 2
3.6.5.10.2. Reclaiming Unused Resources
$> lbtipc_resource_manager -reclaim Reclaiming Resources Process 24441 not found: reclaiming Memory resource (SessionID: ab569cec XPortID: 20001) Process 24441 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 1 Process 24436 not found: reclaiming Semaphore resource: Key: 0x68871d75 Sem Index: 2
3.6.5.10.3. Discovering Resources In Use
$> lbtipc_resource_manager -reclaim Reclaiming Resources Process 24441 still active! Memory resource not reclaimed (SessionID: ab569cec XPortID: 20001) Process 24441 still active! Semaphore resource not reclaimed (Key: 0x68871d75 Sem Index: 1) Process 24436 still active! Semaphore resource not reclaimed (Key: 0x68871d75 Sem Index: 2)
3.6.6. Transport LBT-RDMA
The LBT-RDMA transport is Remote Direct Memory Access (RDMA) UM transport that allows sources to publish topic messages to a shared memory area from which receivers can read topic messages. LBT-RDMA runs across InfiniBand and 10 Gigabit Ethernet hardware.
Note: Use of the LBT-RDMA transport requires the purchase and installation of the Ultra Messaging® RDMA Transport Module. See your Ultra Messaging representative for licensing specifics.
Note: Transport LBT-RDMA is not supported on the HP NonStop platform.
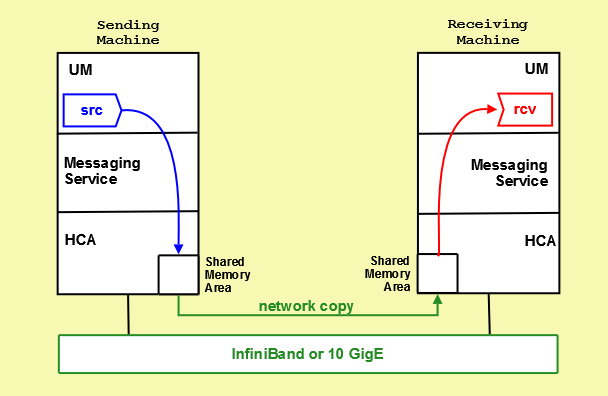
When you create a source with lbm_src_create() and you've set the transport option to RDMA, UM creates a shared memory area object on the sending machine's Host Channel Adapter (HCA) card. UM assigns one of the RDMA transport ports to this area specified with the UM context configuration options, transport_lbtrdma_port_high and transport_lbtrdma_port_low. You can also specify a shared memory location outside of this range with a source configuration option, transport_lbtrdma_port, to prioritize certain topics, if needed.
When you create a receiver with lbm_rcv_create() for a topic being sent over LBT-RDMA, UM creates a shared memory area on the receiving machine's HCA card. The network hardware immediately copies any new data from the sending HCA to the receiving HCA. UM receivers monitor the receiving shared memory area for new topic messages. You configure receiver monitoring with transport_lbtrdma_receiver_thread_behavior.
3.6.6.1. LBT-RDMA Object Diagram
The following diagram illustrates how sources and receivers interact with the shared memory area used in the LBT-RDMA transport.
3.6.6.2. Similarities with Other UMS Transports
UM functions in much the same way as if you send packets across a traditional Ethernet network as with other UM transports.
-
If you use a range of ports, UM assigns multiple topics that have been sent by multiple sources in a round robin manner to all the transport sessions configured my the port range.
-
Transport sessions assume the configuration option values of the first source assigned to the transport session.
-
Sources are subject to message batching.
-
Topic resolution operates identically with LBT-RDMA as other UM transports albeit with a new advertisement type, LBMRDMA.
3.6.6.3. Differences from Other UMS Transports
-
Unlike LBT-RM which uses a transmission window to specify a buffer size to retain messages in case they must be retransmitted, LBT-RDMA uses the transmission window option to establish the size of the shared memory.
-
LBT-RDMA does not retransmit messages. Since LBT-RDMA transport is essentially a memory write/read operation, messages should not be be lost in transit. However, if the shared memory area fills up, new messages overwrite old messages and the loss is absolute. No retransmission of old messages that have been overwritten occurs.
-
Receivers also do not send NAKs when using LBT-RDMA.
-
LBT-RDMA does not support Ordered Delivery. However, if you set ordered_delivery 1 or -1, LBT-RDMA reassembles any large messages.
-
LBT-RDMA does not support Rate Control.
-
LBT-RDMA creates a separate receiver thread in the receiving context.