10. Fault Tolerance
This section discusses the following.
10.1. Configuring for Persistence and Recovery
Deployment decisions play a huge role in the success of any persistent system. Configuration in UMP has a number of options that aid in performance, fault recovery, and overall system stability. It is not possible, or at least not wise, to totally divorce configuration from application development for high performance systems. This is true not only for persistent systems, but for practically all distributed systems. When designing systems, deployment considerations need to be taken into account. This section discusses the following deployment considerations.
10.1.1. Source Considerations
Performance of sources is heavily impacted by:
-
the release policy that the source uses
-
streaming methods of the source
-
the throughput and latency requirements of the data
Source release settings have a direct impact on memory usage. As messages are retained, they consume memory. You reclaim memory when you release messages. Message stability, delivery confirmation and retention size all interact to create your release policies. UMP provides a hard limit on the memory usage. When exceeded, a Forced Reclamation event is delivered. Thus applications that anticipate forced reclamations can handle them appropriately. See also Source Message Retention and Release.
How the source streams data has a direct impact on latency and throughput. One streaming method sets a maximum, outstanding count of messages. Once reached, the source does not send any more until message stability notifications come in to reduce the number of outstanding messages. The umesrc example program uses this mechanism to limit the speed of a source to something a store can handle comfortably. This also provides a maximum bound on recovery that can simplify handling of streaming source recovery.
The throughput and latency requirements of the data are normal UM concerns. See Ultra Messaging® Concepts.
10.1.2. Receiver Considerations
In addition to the following, receiver performance shares the same considerations as receivers during normal operation.
10.1.2.1. Acknowledgement Generation
Receivers in a persistence implementation of UMP send an a message consumption acknowledgement to stores and the message source. Some applications may want to control this acknowledgement explicitly themselves. In this case, ume_explicit_ack_only can be used.
10.1.2.2. Controlling Retransmission
Receivers in UMP during fault recovery are another matter entirely. Receivers send retransmission requests and receive and process retransmissions. Control over this process is crucial when handling very long recoveries, such as hundreds of thousands or millions of messages. A receiver only sends a certain number of retransmission requests at a time.
This means that a receiver will not, unless configured to with retransmit_request_outstanding_maximum, request everything at once. The value of the low sequence number (Receiver Recovery) has a direct impact on how many requests need to be handled. A receiving application can decide to only handle the last X number of messages instead of recovering them all using the option, retransmit_request_maximum. The timeout used between requests, if the retransmission does not arrive, is totally controllable with retransmit_request_interval. And the total time given to recover all messages is also controllable.
10.1.2.3. Recovery Process
Theoretically, receivers can handle up to roughly 2 billion messages during recovery. This limit is implied from the sequence number arithmetic and not from any other limitation. For recovery, the crucial limiting factor is how a receiver processes and handles retransmissions which come in as fast as UMP can request them and a store can retransmit them. This is perhaps much faster than an application can handle them. In this case, it is crucial to realize that as recovery progresses, the source may still be transmitting new data. This data will be buffered until recovery is complete and then handed to the application. It is prudent to understand application processing load when planning on how much recovery is going to be needed and how it may need to be configured within UMP .
10.1.3. Store Configuration Considerations
UMP stores have numerous configuration options. See Configuration Reference for Umestored. This section presents issues relating to these options.
10.1.3.1. Configuring Store Usage per Source
A store handles persisted state on a per topic per source basis. Based on the load of topics and sources, it may be prudent to spread the topic space, or just source space, across stores as a way to handle large loads. As configuration of store usage is per source, this is extremely easy to do. It is easy to spread CPU load via multi-threading as well as hard disk usage across stores. A single store process can have a set of virtual stores within it, each with their own thread.
10.1.3.2. Disk vs. Memory
As mentioned previously in UMP Stores, stores can be memory based or disk based. Disk stores also have the ability to spread hard disk usage across multiple physical disks by using multiple virtual stores within a single store process. This gives great flexibility on a per source basis for spreading data reception and persistent data load.
UMP stores provide settings for controlling memory usage and for caching messages for retransmission in memory as well as on disk. See Options for a Topic's ume-attributes Element. All messages in a store, whether in memory or on disk, have some small memory state. This is roughly about 72 bytes per message. For very large caches of messages, this can become non-trivial in size.
10.1.3.3. Activity Timeouts
UMP stores are NOT archives and are not designed for archival. Stores persist source and receiver state with the aim of providing fault recovery. Central to this is the concept that a source or receiver has an activity timeout attached to it. Once a source or receiver suspends operation or has a failure, it has a set time before the store will forget about it. This activity timeout needs to be long enough to handle the recovery demands of sources and receivers. However, it can not and should not be infinite. Each source takes up memory and disk space, therefore an appropriate timeout should be chosen that meets the requirements of recovery, but is not excessively long so that the limited resources of the store are exhausted.
10.1.4. UMP Configuration Examples
The following example configurations are offered to illustrate some of the many options available to configuring UMP .
10.1.4.1. UMP Configuration with NAT/Firewall
Although the diagram, Normal Operation, demonstrates the typical message interaction in UMP , sources, receivers, and stores may be arranged in almost limitless configurations. Some configurations make more sense than others for certain situations. One of those situations involves a Network Address Translation configuration (NAT) and/or Firewall. In such configurations, the source is the key element behind the NAT or Firewall. Although not the only viable NAT/Firewall configuration for UMP , the figure below demonstrates one approach to such an arrangement.
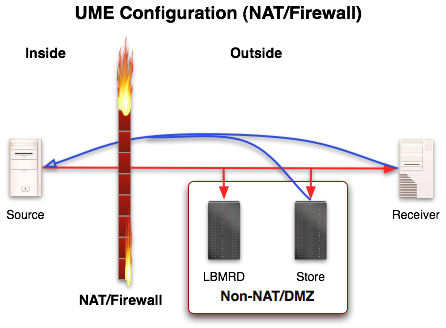
The lbmrd (29west Resolution Daemon) is an optional piece, but used in most situations where a NAT or Firewall is involved. It provides unicast support for topic resolution. The lbmrd and the store are placed on the outside (or at least are non-NATed or on a DMZ). Important characteristics of this configuration are:
-
The LBMRD acts as a proxy for the topic resolution information.
-
The store is accessible by the source and receiver directly.
In this situation, receivers and stores unicast control information back to the source, therefore the NAT or Firewall router needs to port forward information back to the source.
10.1.4.2. Quorum/Consensus - Single Location Groups
Quorum/Consensus provides a huge set of options for store arrangements in UMP . Between backups and groups, the number of viable approaches is practically limitless. Below are two approaches using single location groups and multiple location groups.
In short, as long as one of the groups in the figure maintains quorum, then the source can continue. See Sources Using Quorum/Consensus Store Configuration to view a UM configuration file for this example.
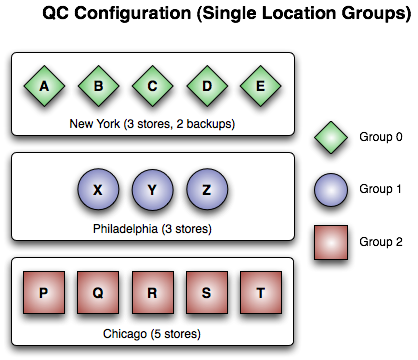
The above figure shows three groups arranged on a location basis. Each group is a single location. Just SOME possible failure scenarios are:
-
Failure of any 3 stores in Group 0
-
Failure of any 1 store in Group 1
-
Failure of any 2 stores in Group 2
-
Failure of all stores in Group 0 and 1
-
Failure of all stores in Group 1 and 2
-
Failure of all stores in Group 0 and 2
10.1.4.3. Quorum/Consensus - Mixed Location Groups
Groups of stores can be configured across locations. Such an arrangement would ensure continued operation in the event of a site-wide failure at any location.
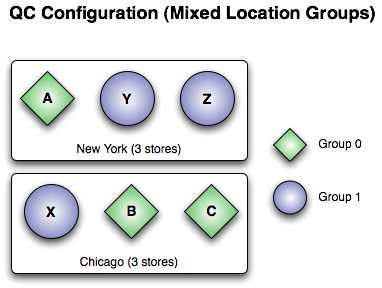
The figure above shows two groups arranged in a mixed location manner. Essentially, one location can totally fail and a source can continue sending because the other location has a group with a quorum. See below for an UM configuration file for this example.
source ume_store 10.16.3.77:10313:101000:0
source ume_store 10.16.3.78:11313:110000:1
source ume_store 10.16.3.79:12313:120000:1
source ume_store 192.168.0.44:15313:150000:1
source ume_store 192.168.0.45:16313:160000:0
source ume_store 192.168.0.46:17313:170000:0
source ume_message_stability_notification 1
source ume_store_behavior qc
source ume_store_group 0:3
source ume_store_group 1:3
source ume_retention_intragroup_stability_behavior quorum
source ume_retention_intergroup_stability_behavior any
10.2. Proxy Sources
The Proxy Source capability allows you to configure stores to automatically continue sending the source's topic advertisements which contain store information used by new receivers. Without the store RegID, address and TCP port contained in the source's Topic Information Records (TIR), new receivers cannot register with the store or request retransmissions. After the source returns, the store automatically stops acting as a proxy source.
Some other features of Proxy Sources include:
-
Requires a Quorum/Consensus store configuration.
-
Normal store failover operation also initiates a new proxy source.
-
A store can be running more than one proxy source if more than one source has failed.
-
A store can be running multiple proxy sources for the same topic.
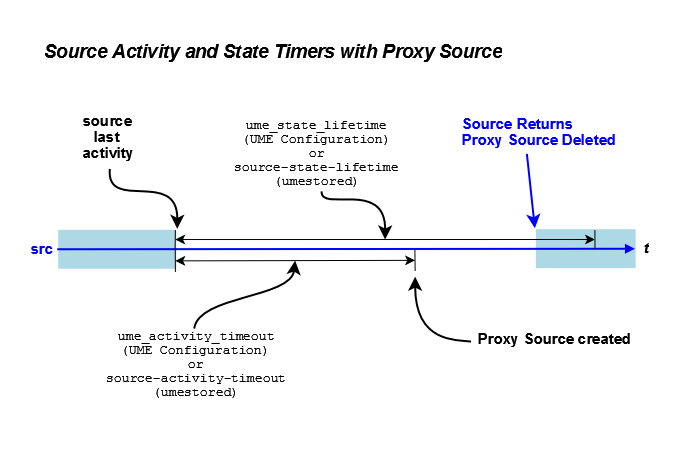
10.2.1. How Proxy Sources Operate
The following sequence illustrates the life of a proxy source.
-
A source configured for Proxy Source sends to receivers and a group of Quorum/Consensus stores.
-
The source fails.
-
The source's ume_activity_timeout or the store's source-activity-timeout expires.
-
The Quorum/Consensus stores elect a single store to run the proxy source.
-
The elected store creates a proxy source and sends topic advertisements.
-
The failed source reappears.
-
The store deletes the proxy source and the original source resumes activity.
If the store running the proxy source fails, the other stores in the Quorum/Consensus group detect a source failure again and elect a new store to initiate a proxy source.
If a loss of quorum occurs, the proxy source can continue to send advertisements, but cannot send messages until a quorum is re-established.
10.2.2. Activity Timeout and State Lifetime Options
UMP provides activity and state lifetime timers for sources and receivers that operate in conjunction with the proxy source option or independently. This section explains how these timers work together and how they work with proxy sources.
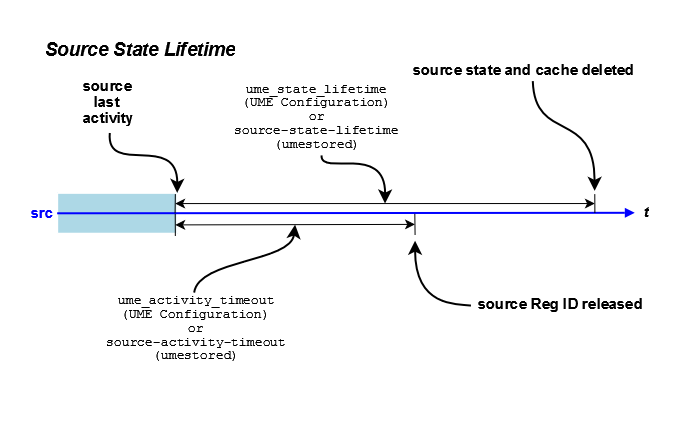
The ume_activity_timeout options determine how long a source or receiver must be inactive before a store allows another source or receiver to register using that RegID. This prevents a second source or receiver from stealing a RegID from an existing source or receiver. An activity timeout can be configured for the source/receiver with the UM Configuration Option cited above or with a topic's ume-attribute configured in the umestored XML configuration file. The following diagram illustrates the default activity timeout behavior, which uses source-state-lifetime in the umestored XML configuration file. (See Options for a Topic's ume-attributes Element.)
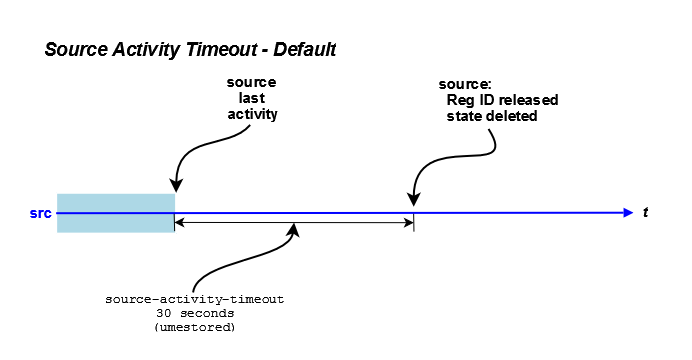
In addition to the activity timeout, you can also configure sources and receivers with a state lifetime timer using the following options.
-
The topic's ume-attributes options, source-state-lifetime and receiver-state-lifetime. See Options for a Topic's ume-attributes Element.
The ume_state_lifetime, when used in conjunction with the ume_activity_timeout options, determines at what point UMP removes the source or receiver state. UMP does not check the ume_state_lifetime until ume_activity_timeout expires. The following diagram illustrates this behavior.
If you have enabled the Proxy Source option, the Activity Timeout triggers the creation of the proxy source. The following diagram illustrates this behavior.
10.2.3. Enabling the Proxy Source Option
You must configure both the source and the stores to enable the Proxy Source option.
-
Configure the source in a UM Configuration File with the source configuration option, ume_proxy_source.
-
Configure the stores in the umestored XML configuration file with the Store Element Option, allow-proxy-source. See Options for a Store's ume-attributes Element for more information.
Note: Proxy sources operate with Session IDs as well as Reg IDs. See Managing RegIDs with Session IDs
10.3. Queue Redundancy
Queues can use the same Quorum/Consensus configuration as UMQ stores.
-
Sources submit queue messages to each queue instance.
-
You configure queue instances into groups using the Queue Groups Element of the queue's umestored XML configuration file. You can configure all queue instances for a queue in a single umestored XML configuration file or a separate file for each instance.
-
A message is considered stable once it has satisfied the stability requirements you configure with umq_retention_*_stability_behavior.
-
Receivers send Consumption Reports to all queue instances so they all are aware of message reception status.
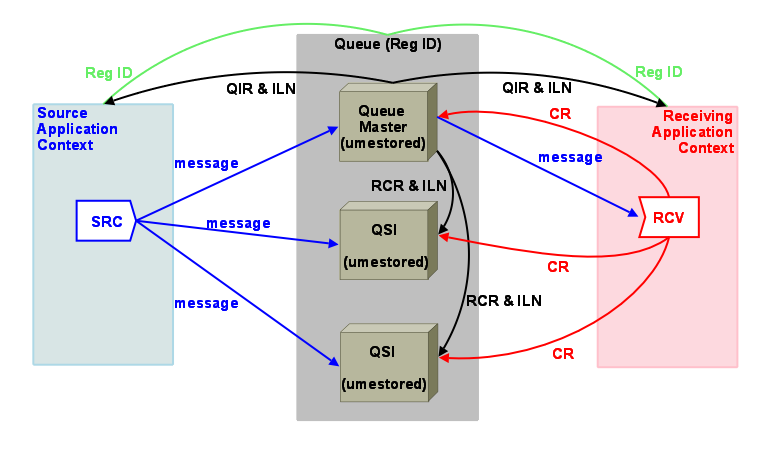
Figure 23 shows how multiple instances of a Queue can be configured and some of the communication between contexts, sources, receivers and Queue instances.
-
RegID - Application contexts register with the Queue using a RegID in order to send messages to the Queue or receive messages from the Queue. See Queue Registration IDs and umq_queue_registration_id.
-
Queue Master - A Queue Instance that has been elected the master Queue. Only the master Queue sends messages to receivers. The master sends Instance List Notifications (ILN) periodically to QSIs and registered contexts.
-
Queue Slave Instance (QSI) - Slave Queue Instances initiated for Queue Failover. Should the master Queue fail, any QSI can assume master Queue activities following election. Each QSI and the master Queue require a separate UM Configuration File and umestored configuration.
-
QIR (Queue Information Record) - Queue advertisement sent by the master Queue to registered contexts which enable sources and receivers to resolve queue names to lists of queue instances (ILN). QIRs contain each queue instances' IP address, port, index, and group index as well as flags indicating if the instance is the Queue Election Master, current master or Post Election Master. The QIR also contains versioning information for instances partitioned due to previous failures.
-
ILN (Instance List Notification) - List of active instances in the Queue used by instances to manage themselves. For each instance the list contains the instance's IP address, port, index, group index and flags indicating if the instance is the Queue Election Master, current master or Post Election Master.
-
CR (Consumption Report) - Indication sent to each Queue Instance that a message has been consumed.
10.3.1. Queue Master Election Process
Queue instances use an internal election process to determine a master queue responsible for making assignments and handling any dissemination requirements. The master is also responsible for tracking queue instance liveness and handling queue resolution duties. Those queue instances that are not the master (slaves) simply act as passive observers of queue activities. Slaves may fail and come online without seriously impacting operations. When a master fails, though, an election occurs. Once the election process establishes a new master, queue operation can proceed.
A queue instance is elected master based on the three values shown below and presented in order of importance.
-
The QSI's queue-management-election-bias configured in it's umestored XML configuration file.
-
The QSI's age computed from the number of messages received and submitted by the QSI. UMQ uses the QSI age if all QSI bias values are equal.
-
An internal QSI index. UMQ uses the QSI index if all QSI bias and age values are equal.
UMQ's default behavior assigns the same election bias to every QSI, which often results in the "oldest", active QSI being elected the master queue. If you wish finer control of the election process, you can configure each Queue Instance with an election bias. You could assign the higher election bias values to the Queue Instances you know are running on the more powerful machines or those with the lowest latency. See Queue Management Options for a Queue's ume-attributes Element for more information.
The following summarizes the Queue Master Election Process.
-
A Queue Slave Instance (QSI) detects the loss of the master if the queue_management_master_activity_timeout expires without any Instance Lists having been sent during the timeout period.
-
The QSI that detected the loss of the master names itself Queue Election Master (QEM).
-
The QEM sends an Election Call to all QSIs, which also identifies itself as the new QEM.
-
All QSIs reply to the Election Call with their "instance vote" which contains their own election bias and "age".
-
The QEM selects the QSI with the highest election bias as the master. If two or more QSIs have the highest bias, the QEM selects the "oldest" of the QSIs with the highest bias. The QSI with the most messages received and submitted is considered the oldest. A third tie breaker is an internal QSI index.
-
The QEM sends out another ILN naming the elected QSI as the Post Election Master (PEM).
-
QSIs confirm receipt of the ILN.
-
QEM sends a Resume Operation message to the PEM.
-
The PEM resumes operation of the Queue (assigning messages to receivers, managing dissemination requirements, tracking QSI health, handling queue resolution traffic) and sends a Instance List Notification flagging itself as the current master.
10.4. Queue Failover
The following sections discuss various queue failover scenarios.
10.4.1. Failover from Loss of Quorum
If the loss of a QSI results in the loss of quorum, the master Queue stops advertising (QIR). As a result, sources lose their registration and subsequent messages sent by the sources return an LBM_EUMENOREG event. (If a source is connected to both a store and a queue, subsequent message sends return an LBM_ENO_QUEUE_REG event.) When quorum is regained by the recovery of the lost QSI or the addition of a new QSI, the master Queue advertises again. Sending and receiving UM contexts can then resolve the Queue again and re-register.
10.4.2. Failover from Loss of Master
If the master Queue fails, the following two events occur.
-
Sources lose their registration and subsequent messages sent by the sources return an LBM_EUMENOREG event. (If a source is connected to both a store and a queue, subsequent message sends return an LBM_ENO_QUEUE_REG event.)
-
The first QSI to detect the loss of the master calls an election. See Queue Master Election Process. After wards, the new master Queue starts advertising, allowing sending and receiving UM contexts to resolve the Queue and re-register.
If, due to a series of failures, a QSI notices that it has stored messages that the master queue never saw, it attempts to resubmit them to the master queue. The master queue either accepts these when it determines that it never saw them, or it rejects the resubmission attempt. If the master queue accepts the resubmit, it marks the message as a resubmission when it assigns the message to a receiver, informing the receiver that it was resubmitted from a QSI.
10.4.3. Other Scenarios
If a receiver fails unexpectedly, the queue does not become aware of this until receiver-activity-timeout expires. In the mean time, the queue continues to assign messages to the receiver until the receiver's portion size is met. When the message-reassignment-timeout expires, the queue reassigns the message to a different receiver and sets the message's reassigned flag to inform the receiving application that the message may have been seen by a different receiver.
Receivers can call lbm_rcv_umq_deregister() or lbm_wildcard_rcv_umq_deregister() to gracefully deregister from
the queue. The queue does not assign any new messages to it.
10.4.4. Failover from Loss of Slave (QSI)
Assuming the master queue is running and assuming quorum has been maintained, QSIs coming and going have little to no impact on queue operation. QSIs are largely passive bystanders. As QSIs come and go from the queue, the master queue notifies the UM contexts registered with the queue via instance list notifications (ILN). These notifications inform the contexts which QSI was added or removed.